Je lis parfois que l'environnement de bureau MATE va mourir parce qu'on ne peut pas faire vivre indéfiniment une vieille techno et parce qu'en face il y a KDE, GNOME et Cinamon qui sont beaucoup plus modernes, etc etc. Mais d'où vient cette idée ? Le projet est toujours vivant et si on en croit les notes de version de la 1.18, le portage vers GTK3 a même été terminé. Et puis qu'y a-t-il besoin de moderniser ? MATE est un fork de GNOME2 donc 15 ans d'expérience et de peaufinage, ça tourne au poil et il ne manque vraiment pas grand chose. Allez en cherchant on va dire que MATE supporte mal le hidpi mais je n'en ai pas besoin.
Après 11 ans d'utilisation de Linux les bureaux qui réinventent la roue sans arrêt me laissent de marbre. Regardons ce qu'on a en face de MATE :
- GNOME3 et ses utilisateurs qui se masturbent sur les nouvelles fonctionnalités à chaque version même s'il ne s'agit que de réimplémentation de choses qui ont été supprimées avant parce que les développeurs ont décidé que c'était mieux pour vous.
- KDE qui repart de zéro presque tous les ans mais subit les mêmes tares, qui considère que LTS = 1 an et qui s'en-tête à coder des milliers de logiciels que personne n'utilise : KMail, KOffice, Konqueror et la liste pourrait s'allonger.
- LXDE déclaré mort au profil de LXQT. Sauf que LXQT c'est vraiment pas stable ni même proposé sur toutes les distributions contrairement à LXDE. C'est un environnement moins austère qu'il n'y parait et il constitue une bonne solution de secours quand même Xfce se révèle trop lourd pour votre machine.
- Xfce dont on annonce la mort chaque année mais qui vit toujours. Il constitue une excellente alternative à MATE même si je regrette un peu le manque d'homogénéité des logiciels. Xubuntu est l'une des meilleures distributions desktop, à mon sens.
Ayant fait le tour des environnements j'en reviens toujours à MATE, Xfce et LXDE que je trouve stables, efficaces et léger. Leur ancienneté ne constitue pas une dette technique, un poids dont on essaie de se débarrasser, ils sont au contraire une solide base pour tous les vieux cons comme moi.
Je lis souvent que le RAID matériel c'est mal car on se retrouve prisonnier du hardware et cela peut poser des problèmes en cas de panne. C'est une idée un peu simpliste c'est pourquoi j'ai décidé de rédiger cet article.
Définition : RAID matériel, semi-matériel, logiciel ?
Même si je pense que tout le monde connaît déjà les différences, voici un petit résumé :
- Logiciel : entièrement géré par le système d'exploitation, ce dernier voit les disques physiques et les utilise pour créer un ou plusieurs périphériques block virtuels qui peuvent ensuite être formatés avec n'importe quel système de fichiers. Sous Linux, c'est md qui remplit ce rôle et il est pris en charge par l'installeur Debian. Il est possible de booter sur du RAID logiciel.
- Matériel : une carte additionnelle disposant d'un contrôleur (CPU + firmware + RAM) sert de couche d'abstraction. Le système d'exploitation ne voit plus les disques, uniquement les grappes (ou unités) gérées par la carte RAID. Il faut parfois un driver additionnel, mais la plupart du temps ils sont en upstream dans le kernel Linux (même avec Debian et son kernel sans blob propriétaire).
- Semi-matériel : aussi appelé fake-RAID, c'est ce qui est proposé sur les cartes mères en complément de l'AHCI et de l'IDE par votre contrôleur de stockage (Intel, JMicron...). Ce dernier agit comme une espèce de parasite et puise dans les ressources système et a besoin de pilotes spécifiques pour être reconnu par le système d'exploitation, sous Linux c'est dmraid, sous Windows ça dépend.<-- Lire entre les lignes : c'est de la merde lowcost et vous ne devez jamais l'utiliser.
- Géré par le FS (ex: ZFS ) : Certains systèmes de fichiers n'ont pas besoin de RAID à proprement parler, ils savent gérer directement la répartition/réplication des données. C'est le cas avec LVM qui dispose d'une implémentation basique ou encore ZFS, le meilleur FS du monde, qui lui dispose de fonctionalités avancées (mirror, stripping, raidz, spares...). <-- Lire entre les lignes : je suis un fanatique de zfs, vous devez l'utiliser.
Mon expérience
Le RAID matériel est souvent le plus simple car abstrait pour l'OS. Le changement des disques se fait à chaud et sur certains modèles il n'y a aucune manipulation à faire pour enclencher la reconstruction de la grappe. Il apporte aussi un gain en performances en raison du cache mais aussi parce qu'il soulage votre système lorsqu'il s'agit de calculer des parités (RAID5,6,50...). Il devient quasiment indispensable si vous souhaitez gérer de très nombreux disques (les cartes mères n'ont souvent pas plus de 8 ports SATA). En revanche, il est vrai que le RAID matériel peut poser des problèmes. Je n'ai jamais vu un contrôleur claquer mais j'ai "souvent" (au moins 3 fois par an sur une dizaine de cartes) subit des lag ou micro-coupures qui peuvent faire passer le système de fichiers en read-only et donc planter le serveur.
Le RAID semi-matériel c'est de la merde, très difficile à faire prendre en charge sous Linux en raison de drivers exotiques non libres. Il puise dans les ressources système pour fonctionner et on ne sait pas comment il se comporte si on change de carte mère ou même si on décide de reset le bios. A réserver au bidouillage ou aux gamers windowsiens qui veulent avoir 2 disques en RAID0 pour gagner en performances (encore qu'un unique SSD les écrase de loin). Mais à fuir en prod.
Le RAID logiciel est le plus sûr, il est upstream, non buggué et le CLI est assez évident. Attention je parle de Linux uniquement, je n'ai pas d'expérience avec le RAID logiciel de Windows. Pensez à installer Grub sur vos deux disques en cas de mirroring (RAID1). En cas de panne du serveur vous pouvez monter vos disques dans une autre machine et récupérer vos données. En cas de changement de disque il y a des opérations à faire en CLI mais ce n'est pas très compliqué.
La gestion par le FS (ZFS) est la méthode la plus souple et la plus puissante puisqu'on élimine une couche. Le FS a accès aux disques et à leur cache et sait comment les gérer et contrôler l'intégrité des données. En plus, en cas de changement de disque l'identification est plus simple et la procédure facilitée. Là encore vous devez faire les opérations en CLI, mais les commandes ZFS sont bien conçues et quasi intuitives.
Conclusion
Tout dépend de l'utilisation du serveur :
- ZFS est à privilégier si votre serveur est destiné à stocker des données (usage NAS ou SAN) très clairement. Et contrairement à ce qu'on pense, il ne faut pas des quantités astronomiques de mémoire vive, 8GB suffisent pour ZFS + vos services habituels (après ça dépend de la quantité de cache ZARC que vous souhaitez avoir).
- Le RAID logiciel pour vos serveurs Linux parce que c'est facile à installer, c'est fiable, et le CLI n'est pas très compliqué quand il s'agit de remplacer un disque.
- Le RAID matériel pour vos serveurs Windows (plus facile pour le boot) ou encore Linux si vous ne souhaitez pas vous embêter à gérer vous-même le RAID ou si vous avez des besoins spécifiques (très grand nombre de disques).
Attention ce titre est volontairement putaclick. Je voulais réagir à ce journal Linuxfr qui m'a beaucoup inspiré : BTRFS ne serait plus le futur. On y apprend que Red Hat laisse tomber le support de Btrfs et il ne sera plus présent dans les futures versions.
Ce n'est pas très rassurant, car sans aller jusqu'à dire que Red Hat fait figure d'autorité dans le libre, leur rayonnement en terme de contribution est tellement important que la grande majorité des distributions décident souvent de faire les mêmes choix. Et c'est compréhensible, c'est une forme "d'union du libre" que certains réclament depuis des années et qui permet de mutualiser les correctifs et évolutions chez les mainteneurs.
Vous allez me rétorquer qu'avec Btrfs c'est différent car c'est un composant upstream de Linux et qu'il n'y a rien à faire en particulier pour l'utiliser, oui sauf que le problème se situe pour le support et le backport des correctifs. Red Hat supporte ses versions 10 ans, cela veut dire qu'il y a un énorme boulot pour intégrer du code récent et changeant dans un kernel stable figé. Beaucoup se reposent sur Red Hat / CentOS, donc si le premier lâche l'affaire, ils suivront.
L'abandon du support de Btrfs est aussi un message fort, en effet Red Hat doit répondre aux attentes de ses clients et c'est notamment ce qui a provoqué le retour en force de xfs que je pensais obsolète depuis des années. Donc il semble qu'il n'y a pas de demande sur le marché et dans les datacenter pour Btrfs. Pourquoi ? Je vais proposer quelques idées.
Personnellement, plus le temps passe et moins je vois d'intérêt à Btrfs. Présenté comme un super système de fichiers moderne de la mort qui tue, son développement semble interminable puisqu'il a débuté en 2007 ! Et non seulement il n'est toujours pas stable, mais en plus toutes les fonctionnalités ne sont pas encore présentes. Sans rentrer dans le détail des possibilités du fs, on se rend compte que presque tout est déjà faisable aujourd'hui avec mdraid et lvm. Et je ne parle même pas de ZFS qui est à des années-lumière devant sur tous les points, qui est stable, éprouvé, et qui rencontre un certain succès. J'en veux pour preuve qu'il est entré dans les dépôts Debian, Ubuntu, et qu'il était déjà présent depuis longtemps chez Archlinux. Même avec les problèmes de licence les distributions choisissent de le supporter !
Ma réflexion me mène donc à une question : Btrfs est-il déjà mort ? Ce projet interminable qui veut concurrencer ZFS sans en avoir les épaules a-t-il une chance de se faire une place ? Étant un convaincu et un fanatique de ZFS je ne pense pas. Les gens qui n'ont pas besoin de fonctionnalités avancées resteront sur ext4, fiable et performant, tandis que les autres se tourneront vers ZFS qui n'est pas si gourmand qu'on le dit et qui offre une souplesse inégalée en terme de gestion des disques, pool et données. Nous verrons ce que l'avenir nous réserve, peut-être qu'une autre distribution réussira à lancer Btrfs.
Mageia 6 est sortie et Sebastien C, ceinture noire de troll et de changement de distribution nous livre un avis assez acide. Très peu d'évolutions sur cette version, une distribution qui se veut à la hauteur de debian sans en avoir les moyens, de trop nombreux bureaux, etc.
Je suis assez d'accord, car si on regarde Mageia quelle est sa force ? Sa communauté, son accessibilité et son centre de configuration. Concernant la communauté, je n'ai pas grand chose à en dire car je n'en fais pas partie mais je ne peux que supposer qu'elle se limite au desktop. En effet je n'ai jamais vu de Mandriva, Mandrake ou Mageia sur les serveurs, c'est 90% de debian/ubuntu et 10% de centos/rhel, le reste est anecdotique. Et si on parle de taille de communauté rien ne battra jamais celle de ubuntu/debian car on trouve énormément de ressources sur le web : forums, mailinglist, stackexchange, wiki, irc...
Concernant l'accessibilité aux débutants je suis assez réservé. Je n'ai jamais compris pourquoi Mageia continue de proposer son propre outil de gestion du réseau au lieu d'utiliser Network-manager comme tout le monde d'autant que ce dernier est bien meilleur pour ce qui touche par exemple au wifi ou aux VPNs. Ensuite je note souvent des comportements pouvant dérouter les débutants, par exemple cette manie du gestionnaire de paquet de vous demander de choisir parmi plusieurs dépendances disponibles lorsque vous souhaitez installer un paquet. Je rajoute qu'à chaque fois que j'ai testé cette distribution dans Virtualbox, après la première mise à jour il devient impossible de booter ce qui est quand même problématique.
Le centre de contrôle, je garde le meilleur pour la fin. Sur papier, c'est l'équivalent du Panneau de configuration de Windows, en pratique c'est totalement obsolète. La configuration du matériel n'est plus nécessaire car automatique (par exemple le pilote vidéo), la configuration des imprimantes fait doublon avec cups ou les interfaces proposées par KDE/Gnome, etc. Au final à part le gestionnaire de paquets il n'y a rien de pertinent en 2017. Pourquoi vouloir tripatouiller un centre de contrôle alors qu'à côté un simple Live CD de ubuntu fonctionne out-the-box ?
Si j'étais utilisateur de Mandriva, à sa mort j'aurai plutôt migré sur debian, opensuse ou fedora qui sont des distributions vivantes, actives avec beaucoup de moyens. Mageia me semble plus proche de l'acharnement thérapeutique, une volonté de conserver des outils et modes fonctionnements qui sont là pour rassurer les utilisateurs sans vraiment avoir une utilité ou une pertinence réelle. Les retards à répétition et l'absence de communication pour la 6e version ont d'ailleurs bien failli confirmer mes dires.
Note : c'est mon avis, il ne constitue pas une vérité absolue mais je l'assume. Vous pouvez m'insulter dans les commentaires si vous le souhaitez.
J'ai fait cette semaine un voyage à vélo et je devais passer de Saint-Malo à Dinard, et pour cela il faut franchir la Rance. Étant donné que c'est un fleuve très large, il n'y a pas 36 solutions : il faut passer par le barrage. Le problème c'est qu'il faut emprunter la D168, et je vous laisse juger :
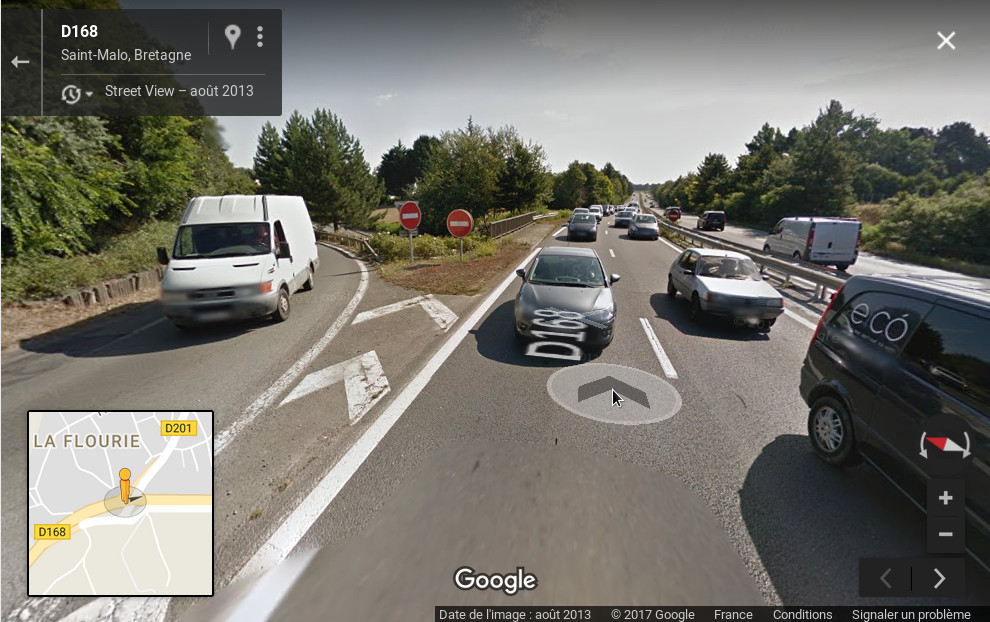
On a donc là une 2x2 voies, limitée en théorie à 70 km/h mais les automobilistes ont tendance à aller beaucoup plus vite sur ce type de route. Pas de piste cyclable, quasiment pas de bande d'arrêt d'urgence. J'ai d'abord refusé de m'engager sur cette route, mais en fait il n'y a pas le choix. Pire, c'est même l'itinéraire touristique du Tour de Manche :
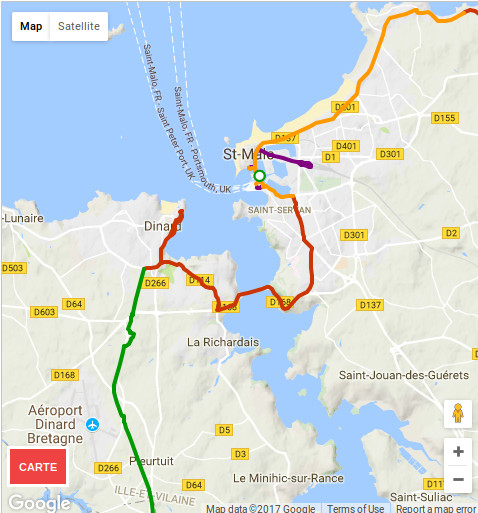
Je ne sais pas quelle commune est responsable, mais c'est du gros foutage de gueule, c'est de la merde, j'avais l'impression de rouler sur une autoroute à vélo et je n'étais "pas rassuré" comme dirait l'autre. Et encore moi ça va car avec le vélo de route je trace, mais imaginez une famille avec des gamins au comportement imprévisible, steak hachés assurés !
J'ai presque envie d'applaudir avec mes deux mains et mes deux couilles cet exploit, une région touristique qui met à ce point en danger les cyclistes ça mérite un award de la pire route de France pour cyclistes.
EDIT : après une petite recherche il s'avère qu'on peut traverser par bateau, c'est bon à savoir mais ça ne change rien à mon coup de gueule, d'autant que si on en croit les commentaires des gens, la traversée est payante.
Fil RSS des articles