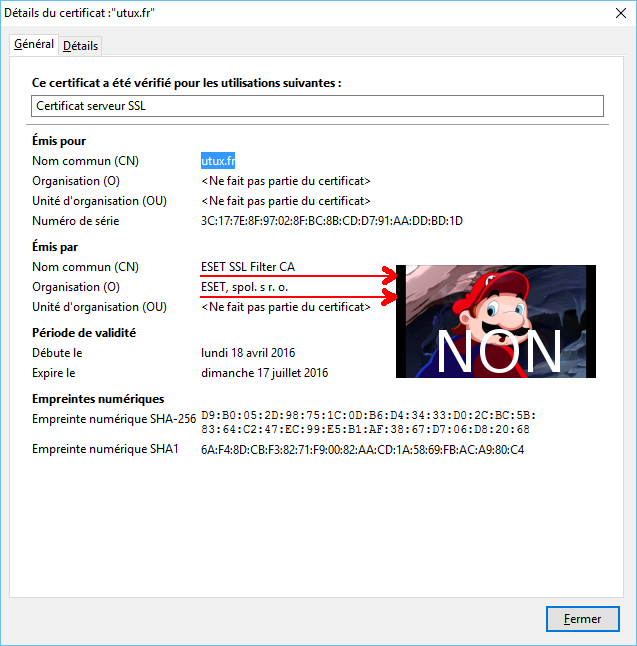
J'ai un ordinateur de gaming sous Windows avec l'antivirus ESET Nod32 (il me restait une licence dans un coin). Et ce matin j'ai remarqué un truc intéressant : ce bougre usurpe l'identité de mes certificats SSL. En effet mon blog, utux.fr, est signé par Let's Encrypt. Or, sur ma machine avec ESET Nod32 installé, voici ce que Firefox affiche :
ESET installe sa propre autorité de certification dans Windows (ce qui rend l'usurpation possible) et re signe les certificats que vous utilisez. Pourquoi ? Le but des certificats signés c'est pas justement de valider la chaîne de confiance jusqu'au serveur ? D'empêcher des interceptions ? Ce que fait ESET Nod32 est justement ce que l'on cherche à éviter non ? Que se passe-t-il si une porte dérobée est découverte dans Nod32 et permet à des personnes mal intentionnées de signer tout et n'importe quoi sur ma machine ?
Tout a commencé avec des problèmes de lenteur sur notre connexion à internet au bureau. Un petit tour dans l'interface d'administration de la Freebox a montré une utilisation importante de la bande passante en upload même la nuit lorsque toutes les stations de travail sont éteintes. Heureusement derrière la Freebox il y a un routeur sous Linux par lequel tout le trafic passe, nous avons donc des outils plus poussés pour analyser ce qui transite.
iptraf a montré que le trafic n'était pas émis depuis une station de travail mais était généré en local (par le routeur lui-même) : était-il compromis ? Présence d'un rootkit ? Une petite vérification des processus avec ps et top semble indiquer que non, rien d'anormal. J'ai également vérifié à coup de md5sum que les binaires bash, ps, w, who, top n'avaient pas été altérés (en comparant avec une version sauvegardée il y a 1 mois).
Donc le routeur génère le trafic mais ne semble pas compromis, d'où vient donc le problème ? Sortons l'artillerie lourde : tcpdump. On sniffe 10secondes de trafic puis on récupère notre fichier pour l'ouvrir dans wireshark, c'est plus simple à lire. L'analyse montre un trafic composé exclusivement de paquets UDP / protocole Portmap. Une petite recherche rapide sur Google "high portmap trafic" me mène vers des articles d'Aout 2015 détaillant une forme de ddos basée sur portmap. C'est un ddos par amplification, c'est à dire que nous recevons des requêtes forgées qui font que nous générons ensuite des attaques vers d'autres serveurs. Or il se trouve que suite à un lourd historique (dette technique) la configuration du pare-feu était incorrecte et le port 111/UDP (portmap) du routeur était accessible depuis internet. La fermeture de ce port a mis fin aux attaques.
tcpdump / wireshark sont les meilleurs amis du sysadmin, et j'ai découvert également iptraf qui permet d'avoir une vue d'ensemble du trafic ce qui permet d'établir un premier diagnostic. Un pare-feu bien configuré est indispensable car même si des services ne sont pas utilisés ou sont censés répondre uniquement en local, des failles sont toujours possibles.
Mon blog a pour sous-titre "le sysadmin qui raconte des histoires". Voici donc le récit d'une nuit passée au datacenter pour remettre en fonctionnement nos serveurs suite à une coupure électrique.
Dans la nuit du 30 Juin au 1er Juillet 2015 un important incident électrique a eu lieu dans l'Ouest de la France, impactant de nombreuses villes en Bretagne et dans les Pays de Loire. J'étais d'astreinte cette nuit là et je ne parvenais pas à dormir en raison de la chaleur (38°c en fin de soirée).
0h00. Je constate que plusieurs de nos serveurs ne répondent pas : absence de ping et pas d'accès IPMI / iDRAC donc impossible de faire quoi que ce soit à distance. Je dois donc me rendre en urgence au datacenter.
01h00. Arrivé sur place je croise d'autres techniciens venus eux aussi réparer leurs serveurs. J'entre mais n'ayant pas le code pour ouvrir la baie je suis obligé d’appeler mon collègue. Celui ci me le fourni et me propose de venir me filer un coup de main : vu la situation j'accepte. Une fois la baie ouverte je fais un contrôle visuel des voyants, tout est au vert, la raison de la panne est donc plus profonde. En branchant un PC sur le switch de la baie je fais un premier diag et je constate que les machines virtuelles sont toutes en carafe ainsi que deux serveurs physiques. Je note aussi que les quelques équipements fonctionnels ont un uptime d'à peine une heure, il y a donc eu un redémarrage général (non prévu).
01h30. J'ai trouvé la cause du non démarrage des VMs : le datastore iSCSI est offline. Heureusement je parviens à le remonter rapidement : le daemon iscsi-target était arrêté sur le SAN. Après l'avoir lancé je remonte les VMs, tout passe sauf quelques vieux serveurs Windows qui affichent des BSOD. Je charge une iso win2k3 puis tente des chkdsk mais rien à faire. Mon collègue est arrivé et a emmené de quoi tenir : des gâteaux et de l'eau. Nous attaquons donc ensemble le diagnostic de ces VMs Windows qui ne veulent pas démarrer et comprenons qu'il faut les mettre sur même serveur Xen qu'avant leur exctinction. En effet notre infra Xen est composée de 3 serveurs reliés à un datastore et les VMs peuvent démarrer dessus au choix. Cela ne pose pas de problèmes pour Linux, en revanche un vieux Windows n'aime pas. Nous faisons donc plusieurs essais jusqu'à trouver le serveur qui leur convient, nous paramétrons ensuite Xen pour que ces VMs précisent ne puisse démarrer que sur celui-là.
03h00. Les machines virtuelles sont maintenant fonctionnelles mais pas certains serveurs physiques, nous cherchons donc la raison. En fait un switch réseau a perdu partiellement sa configuration, probablement parce qu'elle n'a pas été sauvegardée dans la flash. En effet si vous avez fait du Cisco vous savez probablement qu'il y a plusieurs niveaux de sauvegarde de la configuration : le running-config (effacé au redémarrage) et le startup-config (permanent). Après avoir réaffecté les VLANs aux bons ports, les serveurs physiques repassent enfin en UP, sauf un.
03h30. Sur ce serveur réticent nous branchons un écran + clavier et constatons qu'il est bloqué au niveau de Grub. Après avoir booté un LiveCD de Gparted nous lançons une réparation du RAID1 logiciel qui est cassé à l'aide de mdadm. Mais la reconstruction ne suffit pas, Grub refuse toujours de booter. Nous démarrons alors à nouveau sur le LiveCD et faisons un chroot pour réinstaller Grub, à coup de update-grub et grub-install (sur sda puis sdb). Cette fois ça fonctionne !
04h30. Échange téléphonique avec le CTO qui nous aide à vérifier que tous les services sont bien rétablis. Nous corrigeons les derniers problèmes existants.
6h00. Nous partons nous coucher pour pouvoir attaquer la journée à 09h00. En ouvrant la porte de sortie du datacenter je constate qu'il fait jour et que le sol est humide alors que j'y suis rentré de nuit sous une chaleur étouffante. J'aperçois aussi d'autres techniciens aller et venir avec des serveurs sous le bras, nous ne sommes donc pas les plus malchanceux.
Résumé : Une brève coupure électrique a provoqué l’extinction puis l'allumage de nos équipements. 1 serveur physique a cassé son RAID1, le datastore pour Xen n'a pas correctement démarré, et le switch a perdu partiellement sa configuration. Malgré la fatigue nous avons gardé la tête froide, aidés par l'adrénaline et les gâteaux. Nous avons résisté à cette épreuve du feu, en équipe, et avons gagné 1 journée de repos en compensation.
Le HP Proliant Gen8 G1610T format micro tour est un petit serveur en forme de cube ayant la particularité d'offrir 4 baies de disque. Il est totalement silencieux avec une consommation électrique maîtrisée et est proposé à un prix abordable. Il existe en version Intel Celeron ou Intel Xeon, la première étant trouvable à moins de 300 euros (j'ai eu le miens à 226€ neuf chez Amazon en Septembre). Ce n'est pas si cher si on le compare à un NAS Synlogy d'autant qu'on a droit à du hardware beaucoup plus intéressant :
CPU Intel Celeron G1610T (double cœur, 64 bits, virtualisation)
2GB de RAM ECC (extensible)
2 cartes réseau gigabit
iLo (KVM IP)
Un emplacement PCI Express 16x format low profile.
On a donc un vrai serveur sur lequel on peut mettre l'OS de son choix et faire de la virtualisation.
Après avoir mis 8GB de RAM ECC ainsi que 4 disques de 1To dans les baies, j'ai installé FreeNAS sur une clé USB. Au démarrage le ventilateur souffle fort (puisqu'on a affaire à un vrai serveur) mais il ralenti progressivement pour devenir quasiment inaudible. C'est simple : ce serveur fait moins de bruit qu'une Bbox Sensation fibre.
Les disques en cours d'ajout dans les baies.
Je connaissais déjà un peu FreeNAS mais il y a quelques années encore je n'étais pas très familier avec ZFS et FreeBSD. Aujourd'hui je le suis beaucoup plus et je découvre donc à quel point ce produit est bon. Quelle joie d'avoir à portée de main les outils pour gérer un zpool, programmer des scrub périodiques, des snapshots avec durée de rétention, des dataset, des périphériques block...
Bien entendu FreeNAS est orienté NAS donc au delà de ZFS on a les fonctionnalités de partage Windows, UNIX et Apple ainsi qu'une gestion complète des utilisateurs (intégration LDAP ou AD possible).
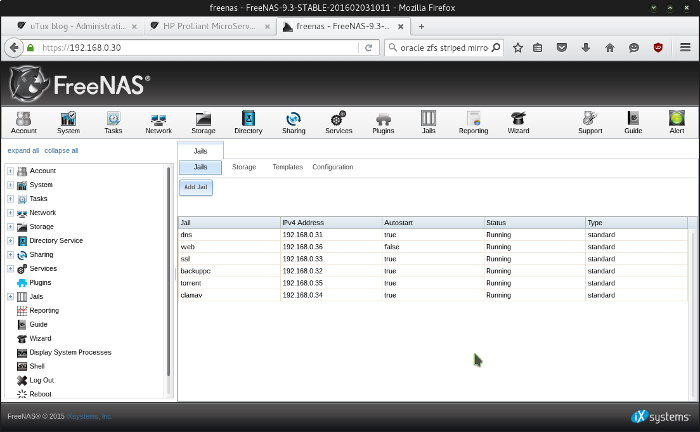
Les sysadmin FreeBSD seront ravis de noter la présence des jails. Si vous voulez que votre NAS fasse office de serveur DNS, il suffit de créer une jail qui tournera sur FreeBSD 9.3 et dans laquelle vous pourrez configurer named. Backuppc ? Idem, une jail avec les ports qui vont bien (ou pkg).
Mes jails sur FreeNAS.
Pour le stockage j'ai testé deux configurations :
4 disques en raidz-1, similaire à du RAID5 : 3TB utiles
2 disques en mirror + 2 disques en mirror, similaire à du RAID10 : 2TB utiles.
La première configuration semble la plus avantageuse car elle offre la plus grosse capacité de stockage mais souffre de mauvaises performances en écriture sans que je comprenne réellement pourquoi (bloqué à 30Mo/s). Refaire le zpool avec 3 disques + 1 spare règle le problème mais c'est dommage d'avoir un disque inutilisé. Il faut noter aussi que beaucoup de sysadmin déconseillent le raidz-1/RAID5 en raison de la reconstruction stressante en cas de changement de disque. Cet excellent article résume la situation. La deuxième configuration en mirror+mirror n'offre que 2TB de stockage (50%) mais fonctionne mieux et la maintenance est facilitée. Voici mon zpool de stockage "data" :
[root@freenas] ~# zpool status
pool: data
state: ONLINE
scan: scrub repaired 0 in 1h38m with 0 errors on Wed Jan 20 03:38:41 2016
config:
NAME STATE READ WRITE CKSUM
data ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
gptid/094171e0-69d3-11e5-81a0-d0bf9c46b918 ONLINE 0 0 0
gptid/0a481bb7-69d3-11e5-81a0-d0bf9c46b918 ONLINE 0 0 0
mirror-1 ONLINE 0 0 0
gptid/0b1b6253-69d3-11e5-81a0-d0bf9c46b918 ONLINE 0 0 0
gptid/0bf02931-69d3-11e5-81a0-d0bf9c46b918 ONLINE 0 0 0
errors: No known data errors
Explication : le zpool data est composé de deux vdev additionnés : mirror-0 et mirror-1. Chaque mirror est composé de deux disques qui, comme leur nom l'indique, sont en miroir (comme du RAID1). Notez qu'il n'y a pas de "stripping" comme dans le RAID10 entre mirror-0 et mirror-1, les données sont écrites là où il y a de la place. L'avantage est qu'on peut avoir deux vdev de taille différente. Par exemple mirror-0 pourrait faire 1TB et mirror-1 faire 2TB, le zpool aurait donc une taille de 1+2 = 3TB là où un RAID10 s'alignerait sur le plus petit et n'aurait donc que 2TB disponibles. ZFS permet aussi de remplacer les disques au fur et à mesure et augmenter la taille du stockage, le tout à chaud. Pour la petite histoire, je l'ai déjà fait sur un serveur de production en remplaçant des disques de 2TB par des 4TB, le zpool est passé de 4 à 6 puis à 8TB.
La compression lz4 est activée par défaut dans FreeNAS car avantageuse en terme de stockage mais aussi de performances. En effet le coût CPU est faible et la réduction du nombre de blocs physiquement écrits et lus améliore la rapidité.
En conclusion le HP Proliant G1610T est le serveur que j'attendais depuis des années. Silencieux, peu gourmand mais néanmoins véloce, il a tout d'un grand surtout les baies de disque qui permettent de faire du stockage. Associé à FreeNAS, il bat toutes les solutions propriétaires du marché et se révèle beaucoup plus souple pour un sysadmin comme moi qui ne jure que par les produits qui offrent un vrai accès root.