Windows Update a toujours été d'une lenteur extrême, à se demander s'il ne recompile pas l'intégralité de l'OS à chaque fois, mais il a toujours plus ou moins bien fonctionné. Ce n'est plus vrai depuis l'arrivée de Windows 10 sur le marché et on observe de plus en plus de dysfonctionnements pour Windows 7 : j'en parle dans mon article Complot : Microsoft a-t-il saboté Windows Update sur Windows 7 ?.
Bonne nouvelle, il existe une solution alternative : WSUS Offline Update. Ce logiciel va vérifier, télécharger et installer les mises à jour. L'outil est très léger, ne nécessite pas d'installation, et fonctionne très bien.
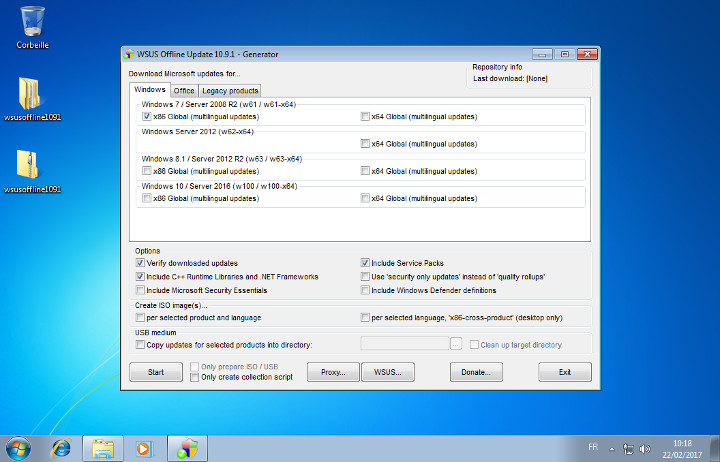
Commencez par exécuter UpdateGenerator.exe puis sélectionnez la ou les versions de Windows concernées (Windows 7, 8.1 ou 10) :
Sélection des systèmes cible et des options.
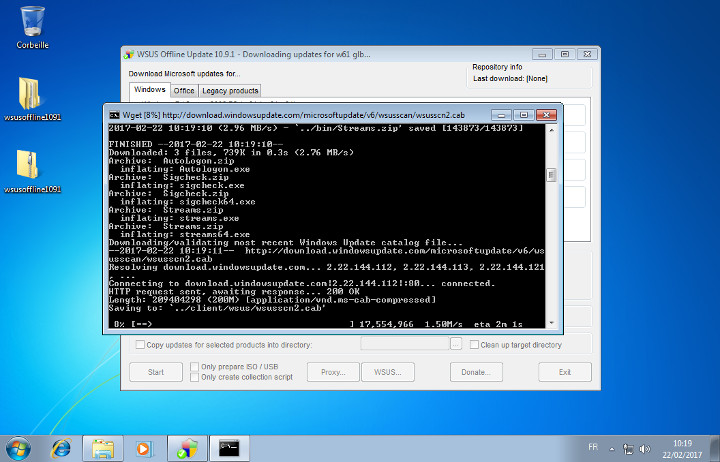
Cliquez ensuite sur Start :
Téléchargement des KB en cours.
Etape 2 : Installation des KB
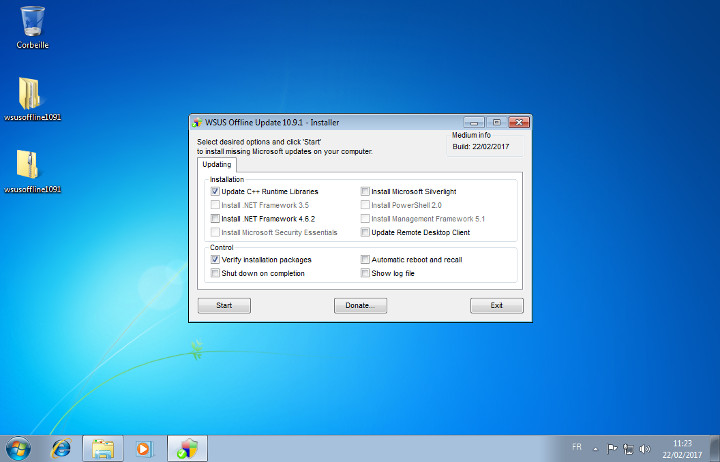
Le support d'installation des KB est maintenant créé. Dans votre dossier wsusoffline/client, exécutez UpdateInstaller.exe :
L'installeur.
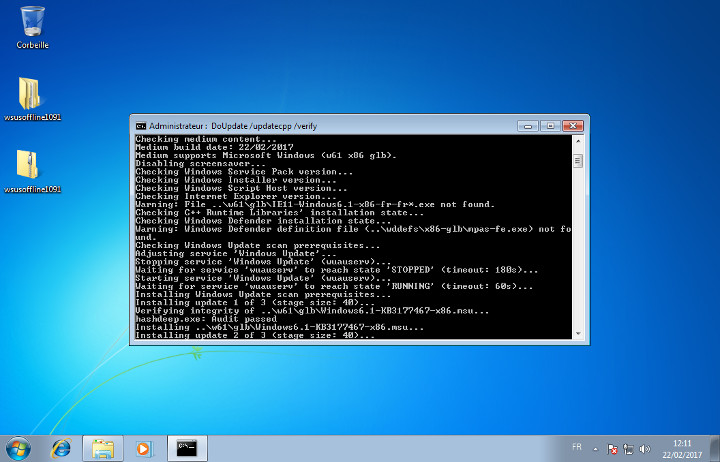
Cliquez ensuite sur Start :
Installation des KB en cours.
A la fin de l'installation, prenez le temps de lire les messages, il est parfois demandé de redémarrer l'ordinateur pour ensuite relancer l'installation de la suite des KB.
Je connais bien OpenBSD pour y avoir fait tourner mon serveur pendant plusieurs mois. J'en ai un bon souvenir, c'est un système simple à comprendre et à configurer grâce à des syntaxes humainement lisibles dans les fichiers de configuration. Malheureusement OpenBSD est encore primitif sur de nombreux points, par exemple les mises à jour. En fait il n'y a aucun dispositif de mise à jour, il faut télécharger les sets en .tgz et les décompresser en écrasant le système, voire même tout recompiler. Deux autres problèmes majeurs que je vois sont d'une part le fs UFS vieillissant et lent (surtout si on compare à FreeBSD et son ZFS) et d'autre part les ports pas toujours à jour car il y a beaucoup moins de mainteneurs disponibles. C'est pourquoi je pense qu'OpenBSD est bien pour certains usages spécialisés qui peuvent se contenter des daemons de base, mais dans beaucoup d'autres cas il se fait éclater par FreeBSD et Linux, par exemple en usage stockage ou desktop.
A l'époque où j'utilisais OpenBSD (2011), le daemon web était un Apache 1.x lourdement modifié et le projet était en cours de migration vers Nginx. Mais ce dernier a été délaissé à son tour au profil de httpd, un serveur maison. Je n'y ai pas vraiment prêté attention jusqu'à récemment avec la lecture du blog de thuban (ou encore De l'épice pour la pensée) qui m'a rendu curieux. Thuban est tellement amoureux d'OpenBSD que quelques temps après l'avoir essayé, il a migré son serveur et écrit un livre.
Exemple simple
Puisqu'on est sur OpenBSD, la configuration sera forcément humainement lisible et centralisée dans un fichier. Le manpage est consultable ici. OMG UN MANPAGE, MER IL ET FOU ! Et oui, sur Linux les manpage sont souvent imbuvables, mais sur OpenBSD ce n'est pas le cas. Pas de panique, on va faire un exemple ensemble :)
On va simplement configurer notre httpd pour servir une page lorsque l'IP du serveur est appelée.
Voici ce qu'on met dans notre /etc/httpd.conf :
server "default" {
listen on * port 80
}
Par défaut, notre serveur travaillera dans /var/www/htdocs et /var/www/logs. On créé une page html de test :
echo "Hello" > /var/www/htdocs/index.html
On autorise httpd à démarrer :
echo httpd_flags="" >> /etc/rc.conf.local
Puis on démarre httpd :
/etc/rc.d/httpd start
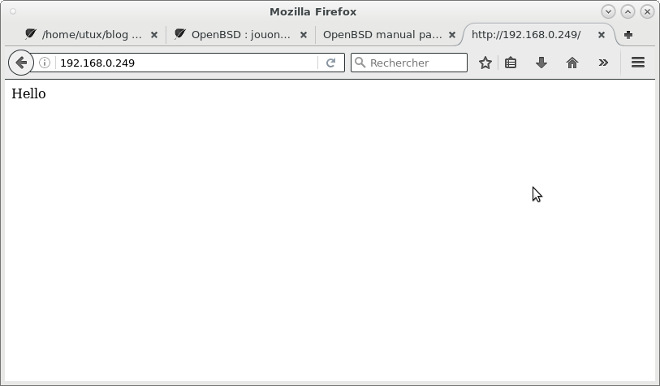
En tapant l'adresse IP du serveur dans votre navigateur, vous devriez avoir le Hello sur fond blanc.
Vous pouvez éventuellement jeter un œil aux fichiers de logs :
On édite notre /etc/httpd.conf dans lequel on va définir nos paramètres globaux, ainsi que nos fichiers splittés de vhost :
chroot "/var/www"
logdir "/var/log/httpd"
include "/etc/httpd/site1.conf"
include "/etc/httpd/site2.conf"
Note : la ligne chroot est inutile ici car sa valeur par défaut est déjà /var/www néanmoins je trouve utile de la préciser, par souci de lisibilité.
/etc/httpd/site1.conf :
server "default" {
listen on * port 80
root "/htdocs/site1"
}
/etc/httpd/site2.conf :
server "ssl" {
listen on * tls port 443
root "/htdocs/site2"
tls certificate "/etc/ssl/cert.pem"
tls key "/etc/ssl/key.pem"
}
Note :root doit être un chemin relatif au chroot. Par exemple le /htdocs/site2 se rapporte implicitement à /var/www/htdocs/site2.
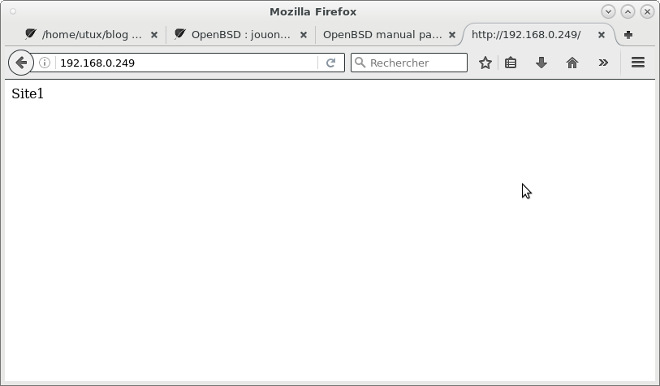
Après avoir rechargé httpd, l'accès à notre serveur en http (port 80) doit afficher le site 1 :
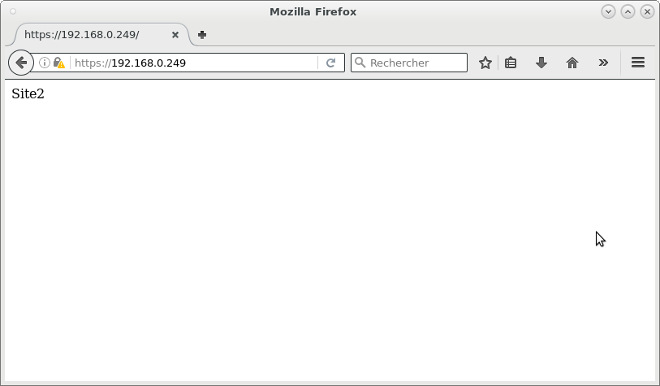
Et l'accès en https (port 443) doit afficher le site 2 :
Conclusion
httpd est un serveur web simple à prendre en main qui ne plaisante pas avec la sécurité, le chroot ayant une place importante dans son fonctionnement. Alors faut-il laisser tomber Apache et Nginx ? Pour un usage basique, c'est à dire servir des pages web, pourquoi pas, car c'est simple et robuste. En revanche, pour des usages avancés, non. À part renvoyer les requêtes dans un socket en fastcgi et servir du contenu statique, on ne peut pas faire grand chose. Pas de reverse proxy par exemple, ce rôle étant confié à relayd. Un autre point agaçant est le fait qu'en cas d'erreur le daemon httpd refuse de démarrer mais n'affiche aucune erreur et ne produit aucun log, donc bonne chance pour debugger.
Si vous êtes un amoureux d'OpenBSD, il est évident que vous ne tarderez pas à migrer vers httpd. Si vous n'êtes qu'un simple Linuxien, j'espère que cet article aura chatouillé votre curiosité.
J'utilise backuppc sur mon NAS à la maison pour sauvegarder mes VPS. J'aime cet outil car il est assez simple et s'appuie sur SSH + rsync des logiciels connus.
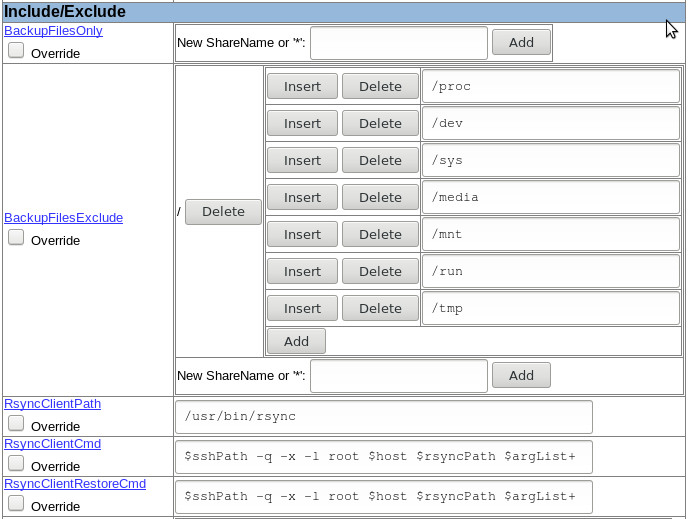
Pour un serveur Linux avec rsync, backuppc va tout sauvegarder à partir de /, ce qui est bien mais il y a des répertoires qu'on a pas forcément envie d'inclure, par exemple /tmp et /run qui sont volatiles ou /mnt qui est utilisé comme point de montage.
Avant je faisais comme ça :
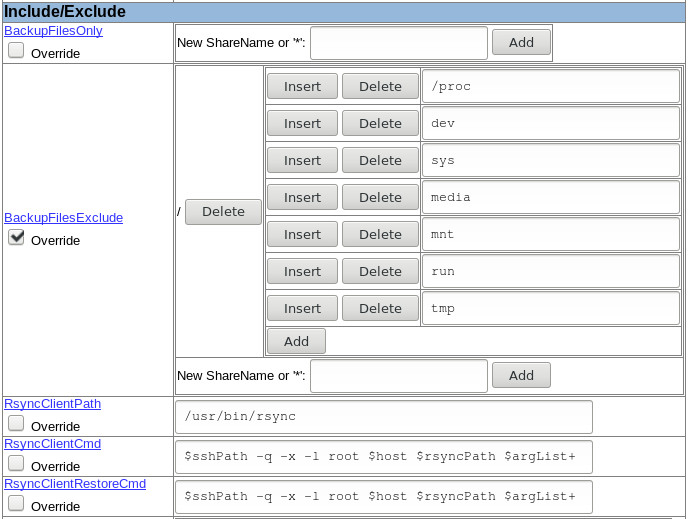
Sauf qu'il s'avère que cette exclusion est un peu violente puisqu'elle ne va pas s'appliquer qu'aux répertoires situés à la racine, mais à tous. Et donc j'ai eu des surprises en constatant que dans ma sauvegarde, /var/www/dokuwiki/data/media était lui aussi exclu, ainsi que /var/www/dokuwiki/data/tmp.
Bon cette fois ce n'était pas méchant, mais voici la bonne pratique pour les exclusions, utiliser des chemins absolus :
J'adore FreeNAS parce que c'est du FreeBSD bien exploité (zfs + jails) et mis en forme proprement au travers d'un webui. J'en parle un peu plus dans cet article et vous encourage toujours à mettre votre NAS propriétaire synlogy et compagnie à la décharge pour vous acheter un vrai serveur digne de ce nom.
FreeNAS 9.10 est disponible depuis peu et se base sur FreeBSD 10.3 ce qui nous amène bhyve, l'hyperviseur concurrent à qemu-kvm très prometteur qui nous permet de faire tourner des VM Linux (entre autres) en plus des jails. Même si cette feature est encore considérée comme expérimentale par FreeNAS, elle est tout même documentée.
FreeNAS fournit l'outil iohyve qui s'inspire de iocage et s'appuie fortement sur zfs. iohyve est génial parce qu'il est non seulement simple à utiliser mais en plus très intuitif car on retient rapidement les commandes. Notez que dans FreeNAS 10 bhyve sera présent dans le webui, pour le moment il faut encore y aller à la main ;)
/!\ Avertissement /!\
Il ne faut pas modifier les fichiers système de FreeNAS, car non seulement ils seront écrasés lors de la prochaine mise à jour, mais en plus ils risquent d'interférer avec le webui. Par exemple au lieu de modifier le /etc/rc.conf on va plutôt aller dans la section tunables qui est prévue à cet effet. On installe pas non plus de paquets avec pkg. Toutes les manipulations du paragraphe suivant font appel à des outils déjà présents qui travaillent dans le zpool contenant les données.
Installation d'une VM ubuntu-server-16.04
La première chose à faire est de configurer iohyve, il va créer ses dataset ainsi que le bridge si celui-ci n'existe pas déjà. Notez que la manipulation n'écrase pas vos dataset ou votre zpool, ne vous embêtez pas à en faire un autre. Dans l'exemple suivant, mon zpool est data et mon interface réseau bge1 :
[root@freenas] ~# iohyve setup pool=data kmod=1 net=bge1
Setting up iohyve pool...
On FreeNAS installation.
Checking for symbolic link to /iohyve from /mnt/iohyve...
Symbolic link to /iohyve from /mnt/iohyve successfully created.
Loading kernel modules...
bridge0 is already enabled on this machine...
Setting up correct sysctl value...
net.link.tap.up_on_open: 0 -> 1
Le dataset Firmware sert pour démarrer des guest en UEFI mais nous ne l'utiliserons pas. Si vous voulez en savoir plus, vous pouvez consulter cette page de wiki détaillant l'installation de Windows avec iohyve.
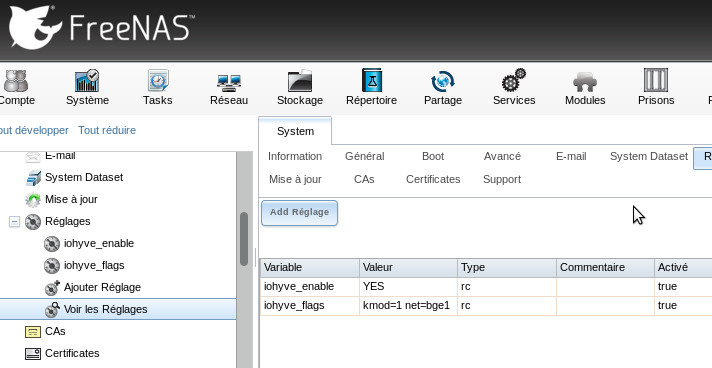
Pour que iohyve et les modules kernel soient chargés au démarrage, on les ajoute dans la section General > Réglages dans le webui de FreeNAS :
Les paramètres ont l'air évidents, mais trois d'entre eux méritent un petit complément :
loader=grub-bhyve : Par défaut iohyve ne va pas charger de bios ou uefi dans bhyve donc il doit utiliser un bootloader externe, ici c'est grub2-bhyve.
ram=1G : pour ubuntu, ne pas mettre moins, j'ai essayé avec 256M et j'ai eu ce bug. Une fois l'installation terminée par contre, on peut baisser.
os=d8lvm : je n'ai pas trouvé beaucoup de détails mais cela indique à iohyve le type de système invité. d8lvm correspond à Debian 8 avec stockage lvm (ce que ubuntu propose par défaut). Sans lvm on peut utiliser os=debian.
Maintenant, on ouvre une seconde console (CTRL+ALT+F2) ou une seconde connexion SSH, puis on se connecte à la console de la VM (il n'y a rien pour le moment, c'est normal, elle ne fonctionne pas) :
[root@freenas] ~# iohyve console vm-ubuntu
On revient sur le premier terminal / SSH, puis on lance l'installation de la VM :
On retourne dans votre second terminal et là on voit enfin des choses apparaître :)
Cela rappelle beaucoup les installations de VM sur Xen.
On fait une installation normale de Ubuntu avec le réseau qui s'auto configure via DHCP. Lorsque c'est terminé, le reboot risque de ne pas fonctionner, il faut donc le faire à la main :
[root@freenas] ~# iohyve stop vm-ubuntu
Stopping vm-ubuntu...
[root@freenas] ~# iohyve list
Guest VMM? Running rcboot? Description
vm-ubuntu YES NO NO Tue Jul 12 22:38:55 CEST 2016
[root@freenas] ~# iohyve start vm-ubuntu
Starting vm-ubuntu... (Takes 15 seconds for FreeBSD guests)
Et la console confirme que ça fonctionne :)
Et voilà, ça fonctionne :)
La VM a même accès au réseau, on peut donc se logguer en SSH !
Conclusion
Encore une fois FreeNAS envoie du lourd et exploite les capacités de FreeBSD. iohyve permet d'utiliser bhyve + zfs tout en étant bien pensé et intuitif, et c'est une qualité rare (regard inquisiteur pointé vers lxd chez Canonical). Il est désormais possible d'avoir des VMs Linux sous FreeNAS ce qui conforte une fois de plus le fait que vous devriez jeter votre NAS propriétaire pour acheter un vrai serveur x86.
Systemd est un système d'init "moderne" qui remplace le vieillissant sysvinit. L'init c'est le premier process qui démarre après le boot et qui va "orchestrer" le lancement des services : réseau, logs, ssh ... Mais wikipedia explique cela mieux que moi.
Dire que systemd a provoqué de nombreuses polémiques et levées de boucliers de la part des utilisateurs est un euphémisme, c'est un beau bazar dans lequel des troll s'affrontent au lance-flammes. On lui reproche de nombreuses choses : réinventer l'eau chaude alors que sysvinit marche bien, être monolithique et donc contraire à la philosophie UNIX, être le cheval de troie de Red Hat pour à terme remplacer de plus en plus de composants dans Linux, ne pas être portable sur les autres OS, etc. Je pense que la plupart des critiques sont vraies et que dans quelques années nos distributions ne seront plus GNU/Linux mais SystemD/Linux. Néanmoins il est intéressant d'observer qu'après 6 ans d'existence, systemd s'est imposé partout à l'exception de Gentoo (+et Slackware) et ce n'est pas par hasard.
Je ne vais pas énumérer point par point les fonctionnalités de systemd, je vais me contenter d'en présenter deux aspects que je trouve intéressants : création d'un service et d'un containers (nspawn).
Création d'un service
Avez-vous déjà écrit des scripts d'init pour un logiciel sur Linux ? Moi oui. Et entre sysvinit et systemd, c'est le jour et la nuit. Prenons pour exemple Nginx :
C'est quand même beaucoup plus simple avec systemd puisqu'une grosse partie du boulot est faite nativement, par exemple la gestion du pid et des logs. Pour sysvinit par contre c'est au développeur du script de prévoir tous les cas, de coder la vérification du pid, des logs, bref c'est long et pas forcément utile puisque même sur Windows on ne fait plus ça depuis 20 ans.
Création d'un container
Systemd est très lié à Linux et aux cgroups, il est possible d'isoler des processus dans leur propre contexte, de là à créer des containers avec une application ou un système entier il n'y a donc qu'un pas qui a été franchit. Pour l'exemple on va créer un container ubuntu-server-16.04 à partir d'une image cloud (pour nous épargner les étapes debootstrap qui n'ont pas vraiment d'intérêt dans cet article) :
Note : sur les versions plus récentes de systemd (non disponible sur Debian Jessie), l'utilitaire machinectl permet de télécharger et déployer une image automatiquement. Voir la section Examples de la documentation machinectl.
Puis démarrer un shell dans le container afin de pouvoir créer un mot de passe root :
root@localhost:~# systemd-nspawn -D /srv/containers/xenial01/
Spawning container xenial01 on /srv/containers/xenial01.
Press ^] three times within 1s to kill container.
/etc/localtime is not a symlink, not updating container timezone.
root@xenial01:~# passwd
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
root@xenial01:~# exit
Maintenant on peut - si on veut - démarrer complètement le container :
root@localhost:~# systemd-nspawn -bD /srv/containers/xenial01/
Spawning container xenial01 on /srv/containers/xenial01.
Press ^] three times within 1s to kill container.
/etc/localtime is not a symlink, not updating container timezone.
systemd 229 running in system mode. (+PAM +AUDIT +SELINUX +IMA +APPARMOR
+SMACK +SYSVINIT +UTMP +LIBCRYPTSETUP +GCRYPT +GNUTLS +ACL +XZ
-LZ4 +SECCOMP +BLKID +ELFUTILS +KMOD -IDN)
Detected virtualization systemd-nspawn.
Detected architecture x86-64.
Welcome to Ubuntu 16.04 LTS!
Ensuite la séquence de démarrage s'affiche et il est possible de se loguer, puis d'arrêter le container avec la commande poweroff :
Ubuntu 16.04 LTS ubuntu console
ubuntu login: root
Password:
Last login: Mon May 23 09:12:29 UTC 2016 on console
run-parts: /etc/update-motd.d/98-fsck-at-reboot exited with return code 1
root@ubuntu:~# poweroff
Si on ne spécifie aucune option au niveau du réseau, le container utilisera l'interface de l'hôte. Attention donc aux services qui écoutent sur les mêmes ports, typiquement SSH, le mieux est encore d'utiliser une interface réseau virtuelle. Je ne rentre volontairement pas dans les détails afin de ne pas faire un article indigeste, mais il est possible d'aller plus loin notamment au niveau des interfaces réseau (bridge, macvlan, veth), des limitations du système (mémoire, cpus...) ou encore de l'intégration avec SELinux. On peut aussi utiliser debootstrap, dnf ou pacstrap pour créer un container (pas besoin d'une image cloud). Pour cela voir la documentation systemd-nspawn et systemd.resource-control (elles ne sont pas si indigestes que ça).
Systemd-nspawn est une alternative intéressante à LXC permettant de gérer des containers thin (on lance uniquement une application) ou thick (on lance tous les services) sans avoir à installer quoi que ce soit.
BONUS : sous debian, ça ne change rien pour les utilisateurs
Si je peux comprendre que beaucoup de gens n'aiment pas systemd et ne souhaitent pas l'utiliser, en revanche je ne comprends pas pourquoi cette grogne est focalisée chez les utilisateurs de debian au point de créer le fork devuan. Parce que si vous êtes utilisateur de debian, systemd ne change rien pour vous. Tout d'abord le boulot est fait par les mainteneurs des paquets, vous n'avez jamais touché à un système d'init de votre vie, et avec systemd vous n'y toucherez pas non plus. Ensuite, si vous faites un peu de sysadmin, là encore rien ne change pour la majorité des opérations.
Voici pour comparer la manière dont on démarre apache :
root@localhost:~# service apache2 start # avec sysvinit
root@localhost:~# service apache2 start # avec systemd
C'est pareil, parce que debian est une distribution pour fainéants (comme moi) très bien foutue. Même chose pour le réseau, ça se gère toujours dans /etc/network/interfaces rien ne change.
Sous Archlinux par contre tout change par exemple le fichier /etc/rc.conf a disparu au profil de fichiers éclatés pris en charge par systemd. Ce n'est pas méchant mais il a fallu réapprendre certaines choses. Malgré une grogne passagère la chose semble avoir bien été acceptée par les utilisateurs, en tous cas ils ne sont pas partis forker leur distribution.
Conclusion
Au final, après avoir lu tant de troll, tant de FUD sur systemd, je trouve que c'est plutôt bien. C'est simple à utiliser et c'est puissant puisqu'on peut imaginer un jour remplacer LXC et cela ouvre plein de possibilités au niveau des serveurs, par exemple avoir des instances apache et nginx isolées dans les containers thin, ou encore des applications portables à la manière de Snap ou xdg-app. Pour 99% des utilisateurs de Linux la transition est transparente puisque prise en charge en amont par les mainteneurs.
Je prends donc le risque d'invoquer une armée de troll dans les commentaires mais moi j'approuve systemd.