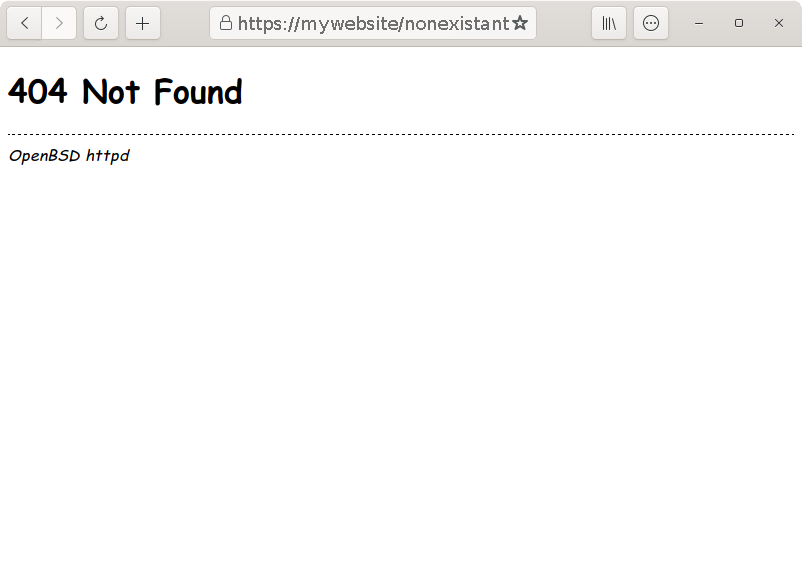
I have been playing with OpenBSD and httpd lately. It's a really simple and fun webserver to use, despite suffering huge limitations, but I quickly stumble across this horror:
No joke. httpd will serve all errors messages with the infamous Comic sans ms font. It's probably a troll from the maintainers, at least I hope so. Comic sans ms sucks, I don't want that on my server. Fortunately, there is a simple way to disable it.
Add this line into your /etc/httpd.conf:
errdocs "/errdocs"
Then create the file /var/www/errdocs/err.html with the following content:
A custom error document may contain the following macros that will be expanded at runtime:
$HTTP_ERROR
The error message text.
$RESPONSE_CODE
The 3-digit HTTP response code sent to the client.
$SERVER_SOFTWARE
The server software name of httpd(8).
So I just took the source code of a 404 error page, removed the Comic sans ms part in the CSS and replaced the values (error code, message, server identity) by the proper variables. Now all errors messages should be generated with this new template, with a fallback font.
If you need to install Zabbix-Agent2 on Ubuntu 16.04, you will find out that there is no available packages in Zabbix repository (unlinke Zabbix-Agent). You can try to use packages for other Linux systems, even RPMs, but you will always end up with library or ABI issues. The only way to make it work is compilation.
wget https://go.dev/dl/go1.19.3.linux-amd64.tar.gz
tar xf go1.19.3.linux-amd64.tar.gz
export PATH=$PATH:/root/go/bin
You should now be able to build Zabbix-Agent 2. I took these options from Zabbix documentation and made some ajustements from what I found in packages in Zabbix repository:
La nouvelle est tombée il y a quelques jours : le support de CentOS 8 se terminera fin 2021 et la distribution basculera à 100% sur le modèle Stream. C'est un changement de gouvernance brutal et destructeur pour ses utilisateurs car CentOS ne sera plus un clone de Red Hat gratuit mais plutôt son pendant "Windows Insider".
Il faut bien comprendre que CentOS c'est quelque chose de gros : c'est la 2e distribution la plus utilisée au monde sur les serveurs Web Linux en 2020 avec 18,8% de parts de marché. Moi qui travaille avec du Cloud et du Linux en entreprise, je confirme que ça représente à la louche 60% de nos serveurs (non Windows) peut-être même plus.
Qu'est-ce qui plaît autant dans cette distribution encore plus en retard que Debian et avec des dépôts tellement vides qu'il n'y a ni nginx ni htop ?
C'est basiquement un clone gratuit de Red Hat, donc très stable et certifiée par des tas de constructeurs de matériel et éditeurs de middlewares.
Support incroyablement long, une dizaine d'années.
Bénéficie de l'énorme documentation en ligne de Red Hat.
La pauvreté des dépôts est compensée par EPEL et SCL (mais aussi tout un tas d'autres).
La version du kernel est vieille mais les drivers et correctifs de sécurité sont backportés dedans.
Certains n'aiment pas les libertés prises par Debian dans le packaging de certaines applications (par exemple Apache). CentOS est un peu plus proche de l'upstream sur ce point.
En gros CentOS était une distribution incassable, prévisible, ennuyeuse, et avec un support extrêmement long. On comprend alors que l'abandon de cette stabilité au profil d'un modèle de type "testing" ou "insider" va totalement à l'encontre de ce qui faisait son intérêt. Mais alors, que peut-on faire ?
Si possible, ne plus déployer de CentOS 8 en attendant que la situation se stabilise. Cette annonce a provoqué de très nombreux retours négatifs de la communauté et il est évident que le projet se rend compte qu'il se saborde lui-même. En ce qui me concerne j'espère soit une annulation de cette décision, soit au contraire un message clair qui indique qu'IBM/Red Hat ne veut plus de CentOS dans sa forme actuelle, dans les deux cas nous serions fixés sur l'avenir.
En attendant, si vous devez déployer de nouveaux serveurs, il existe des alternatives :
Si vous n'avez aucune fidélité à RHEL/CentOS ou aux RPMs, Debian et Ubuntu sont des alternatives de choix. J'ai une nette préférence pour la première que j'ai toujours trouvé plus légère, plus stable, et qui n'installe pas snap par défaut.
CentOS 7 reste une option à ne pas négliger, car supportée jusqu'en 2024.
Si vous avez besoin de la compatibilité RHEL/CentOS 8, il y a Oracle Linux. Alors oui le nom fait peur car quand on parle d'Oracle on pense aux tarifs exorbitants, à OpenOffice, et aux pratiques crapuleuses, il n'empêche que la distribution est bien gratuite et qu'elle perdure depuis 2013, en plus d'être elle aussi un clone de Red Hat. Elle est fournie avec deux kernel : RHCK (compatible Red Hat / CentOS) et UEK (Unbreakable Enterprise Kernel, plus récent et ne nécessitant pas de reboot). Oracle Linux est à mon sens l'alternative la plus crédible à CentOS. Pour couronner le tout, un script de migration est disponible : lien vers un retour d'expérience.
Je ne recommande pas Rocky Linux, c'est beaucoup trop tôt. Des tas de distributions naissent et meurent chaque année, ou se retrouvent parfois dans un état intermédiaire façon Mageia, donc attendons de voir si Rocky aura les moyens de ses ambitions. Elle n'est de toutes manières pas encore disponible.
Il est urgent d'attendre, laissez passer les fêtes pour voir comment la situation évolue. Voilà mon avis sur le feuilleton CentOS ;)
I need to backup my NAS to a remote and secure location, and because I am a Azure AZ-103 associate, I have decided to store my data on a Azure storage account. I will use Duplicati, a free backup software written in C# with the following features:
Storage account offers 3 tier storage with different pricing: hot, cool, archive. If you choose a hot tier, access is less charged, but storage is more expensive. This is the opposite for cool and archive, storage is cheap but access is expensive. Archive is the most interesting tier for backups but it has many constraints, such as the need to pick every object inside the container to move them. So I will use cool right now.
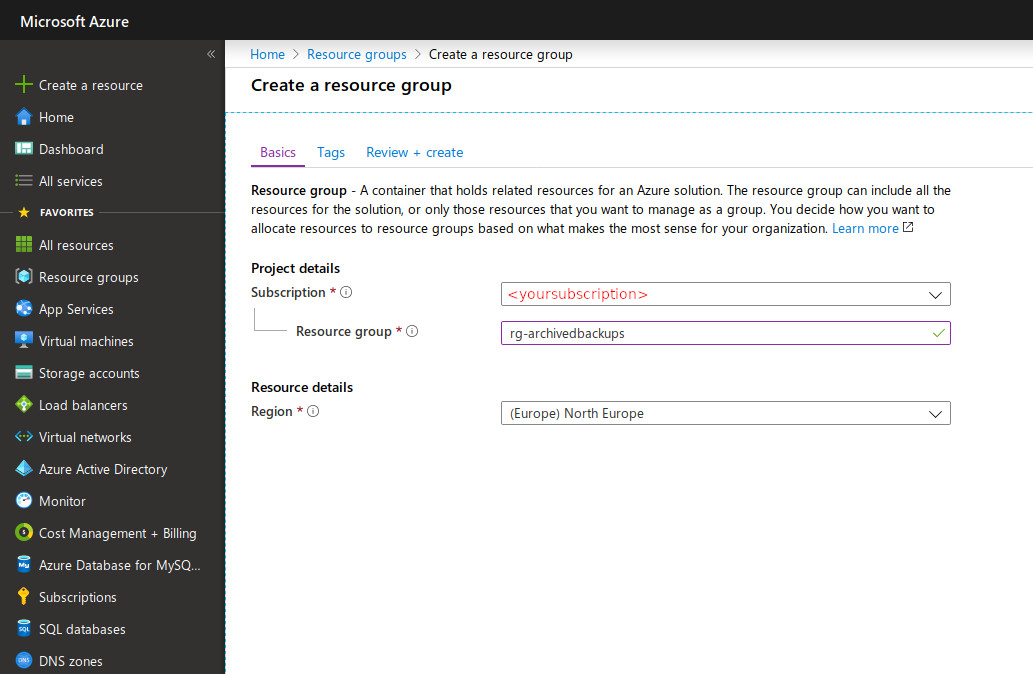
Create a Resource group and a Storage account
First you need to create a Resource group. Go to the Resource groups blade then click +Add. Take a look at Ready: Recommended naming and tagging conventions if you don't know how to name it. Select a region (does not really matters now).
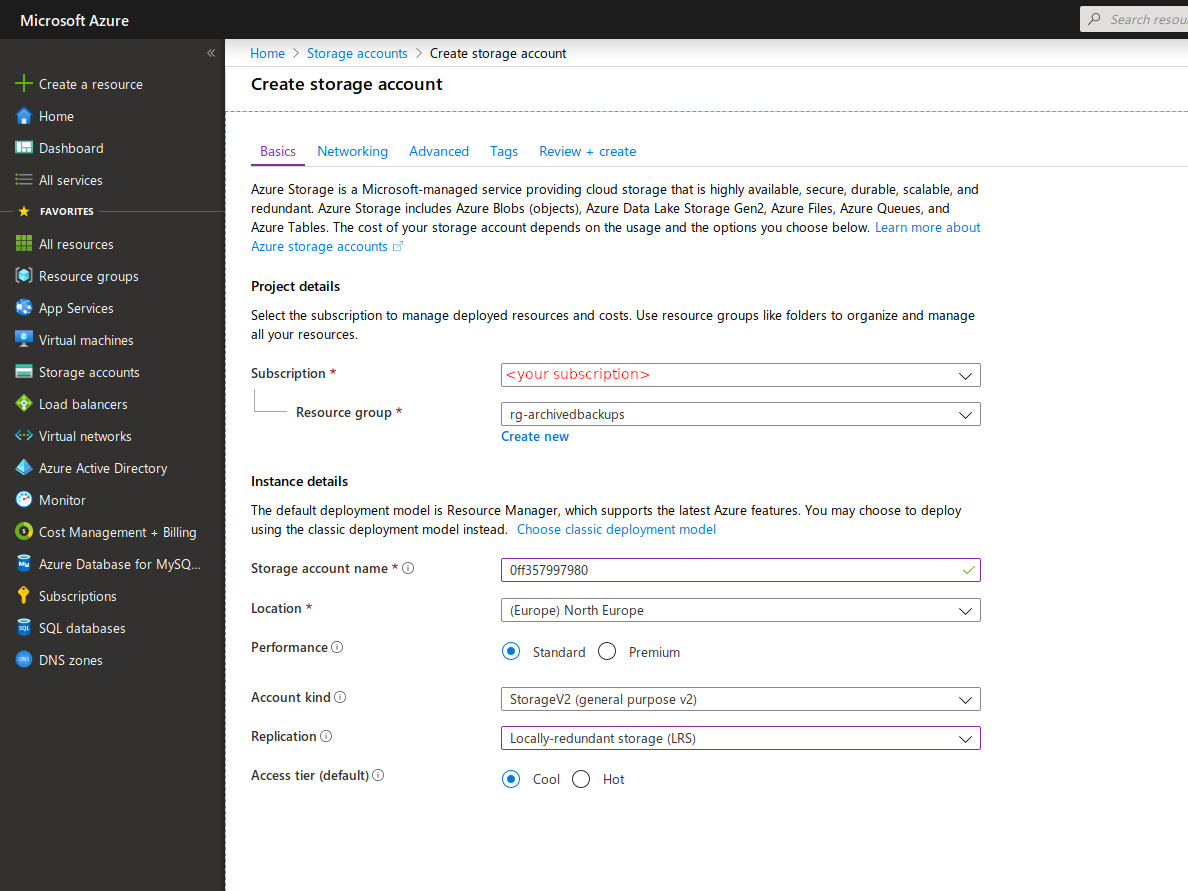
Now you need to create a Storage account. Go to the Storage accounts blade then click +Add.
Subscription: your subscription.
Resource group: the one you just created
Storage account name: must be unique accross Azure and as many limitations, so I recommend using a short name + random id.
Location: Select the location of your choice (choose a close one with an interesting pricing, see Azure Calculator)
Account kind:StorageV2
Replication:LRS
Access tier:cool
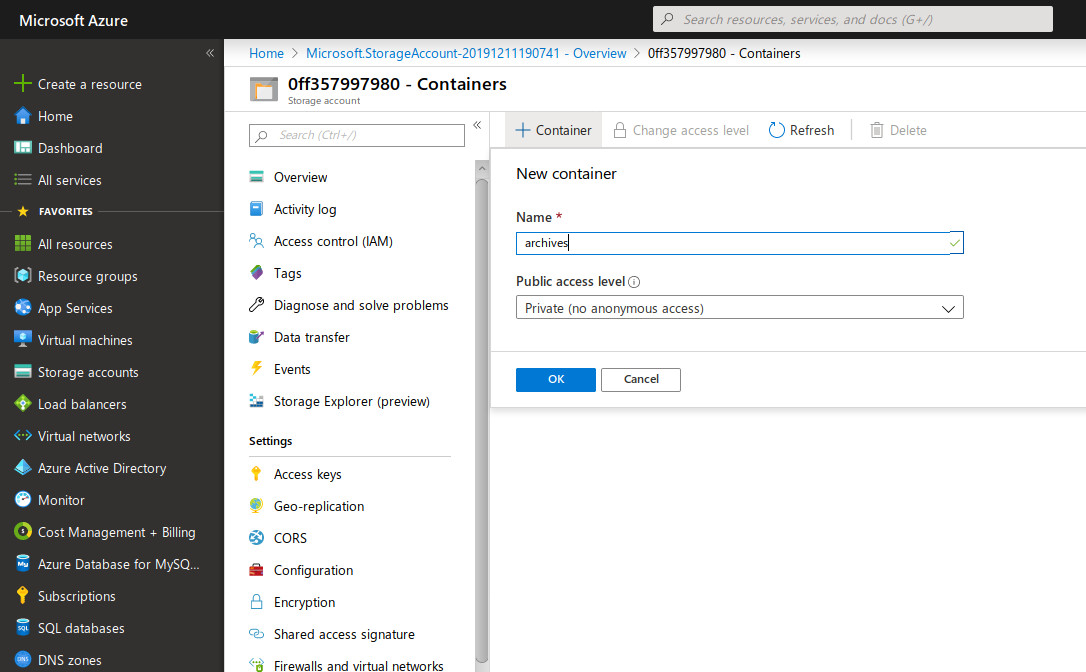
Now open you new Storage account and go to the Containers blade then click +Container. This time the name is private and does not need to be unique. Make sure the Public level access is set to Private (no anonymous access).
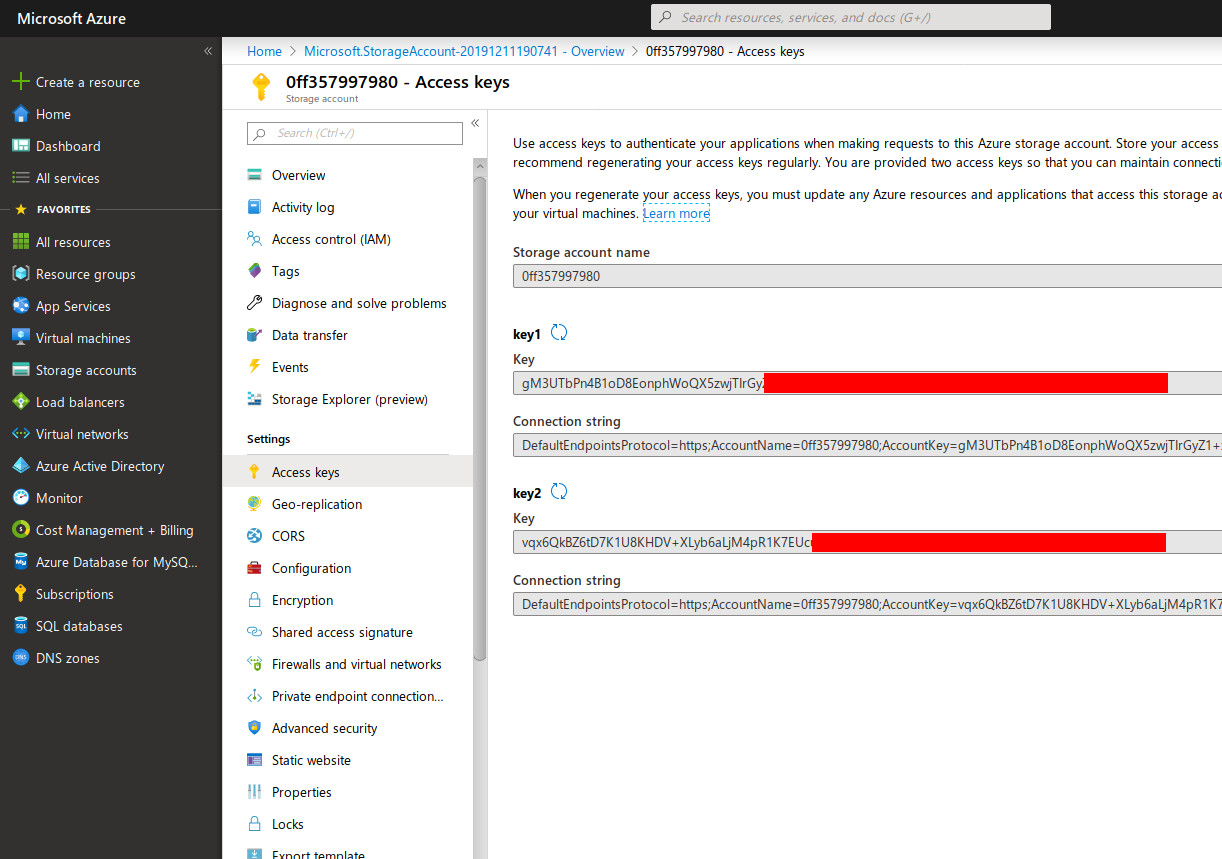
Go to the Access keys blade and retrieve the value of key1 or key2. These key are private and should not be shared with anyone because they basically give full access to the storage account and the data inside.
Configure Duplicati
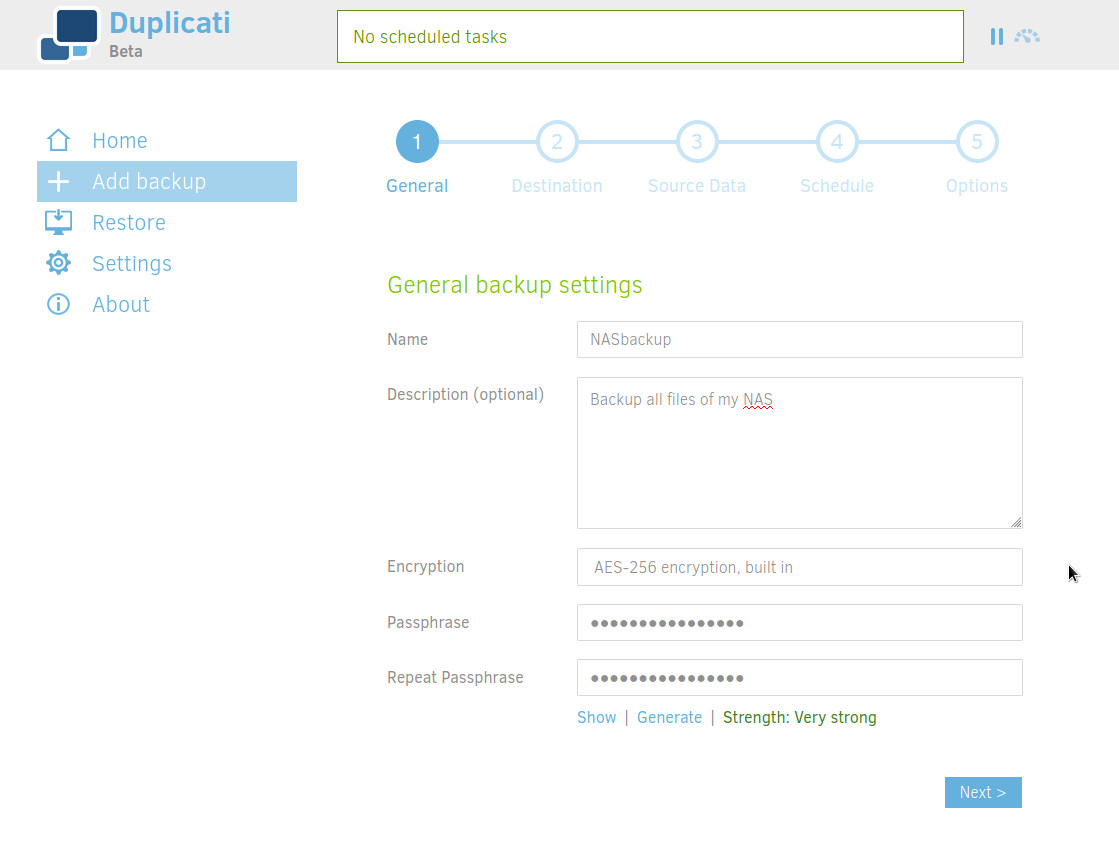
Go into the Web UI then + Add backup > Configure a new backup.
Enter a name, a description and a very strong encryption passphrase. Do not lose it, personally I use Keepass + Syncthing to manage my passwords.
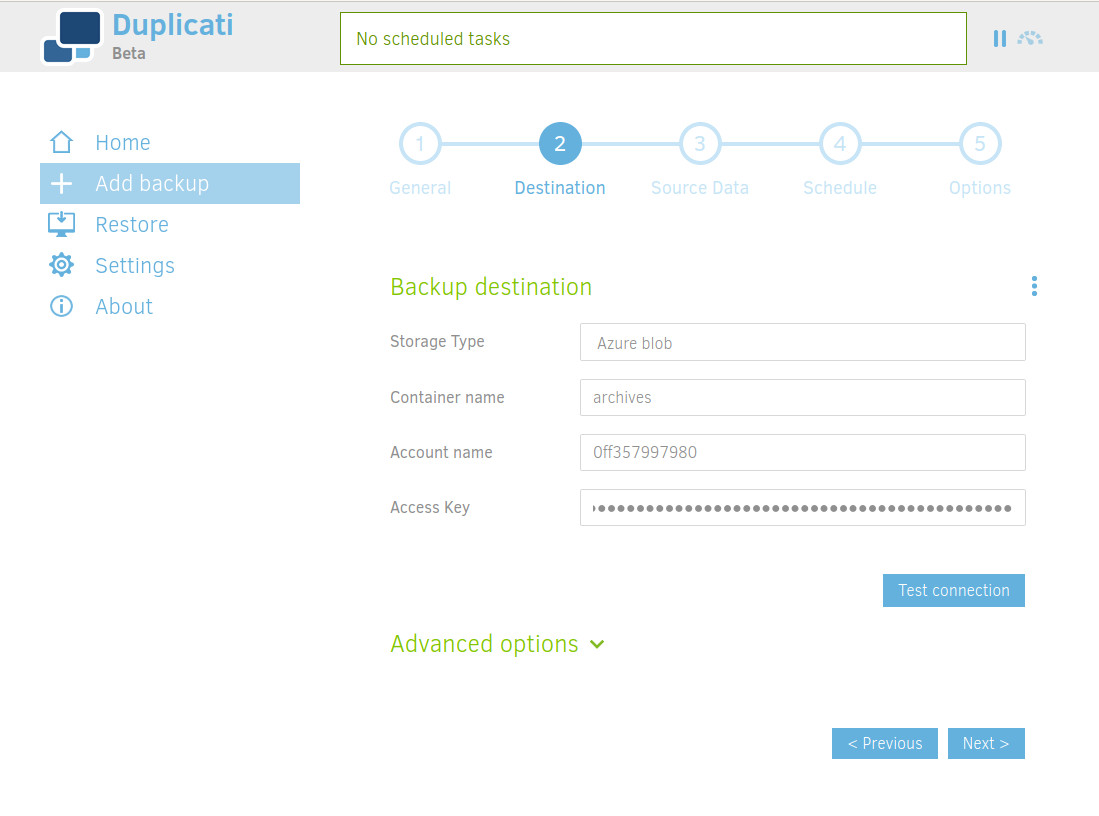
Select "Azure blob" for Storage type and set your credentials.
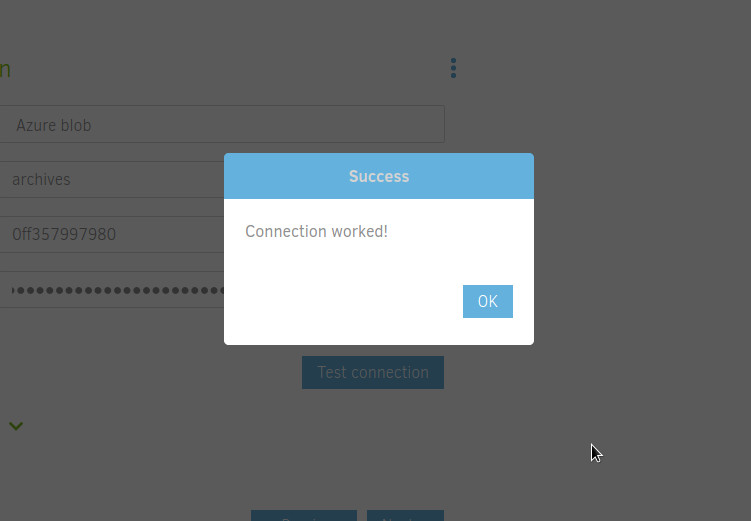
Click Test connection to make sure Duplicati can reach your Azure container.
Select the files you want to backup.
Schedule your backup. For me, monthly is enough.
Duplicati will not copy your files one by one but use "volumes". To select the size of each block, read this documentation. Smaller means more transactions but better de duplication. Bigger means less transactions but less optimized de duplication. If you have the bandwith, go for higher chunks. 1 Gbyte seems to be a good value for me. More is not good because it takes too much resources.
You can also set the retention, for me it's 6 months.
Et voila, just run your backup now!
Cost and Metrics
My Storage Account:
Location: North Europe
Performance/Access tier: Standard/Cool
Replication: Locally-redundant storage (LRS)
Account kind: StorageV2 (general purpose v2)
My Backups:
Data source: ~650 GB
Schedule: @Monthly
Volume size: 1 GB
Used capacity (512 GiB) :
Ingress and Egress (Last executions: 2020/10/10 and 2020/10/14):
Transactions (Last executions: 2020/10/10 and 2020/10/14):
I admit I'm not sure sure why I see transactions when there is no backups. I assume it's Azure stuff.
Last invoice:
Monthly billing is always around €5 which is not cheap but affordable. If you need more than 1TB of storage, it might be a good idea to take a look at Google One (Drive) or Dropbox.
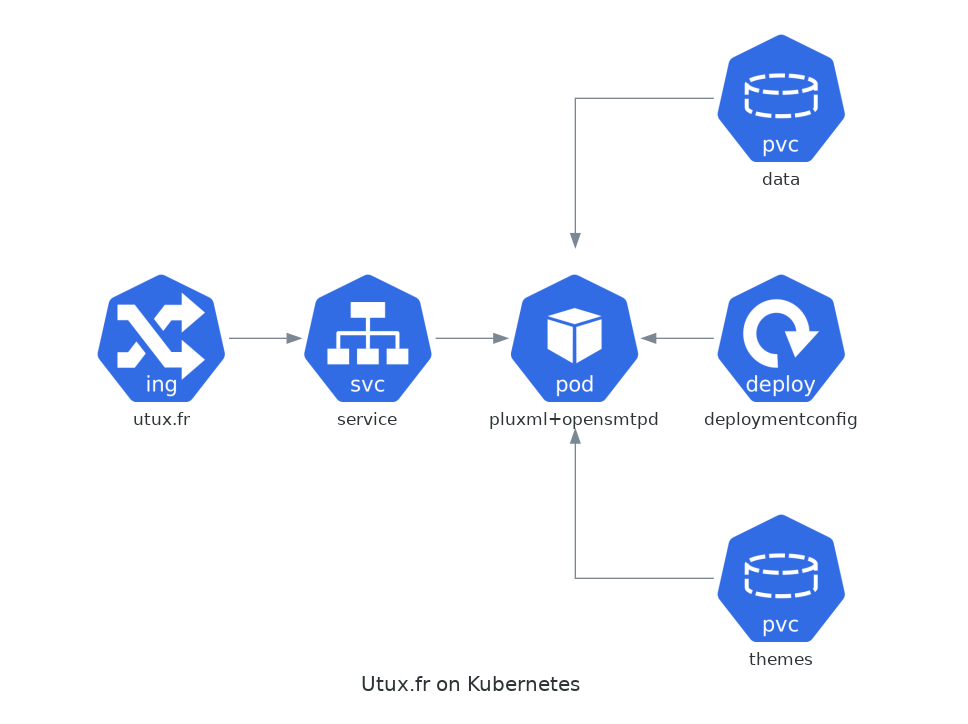
Kubernetes est probablement la technologie la plus complexe sur laquelle j'ai pu travailler cette année, à tel point que j'ai longtemps été réticent à m'y frotter. J'ai tout de même choisi de me faire violence et de persévérer car ce domaine est très valorisant et très valorisé. Utiliser un outil dans le cadre d'un réel besoin est le meilleur moyen pour apprendre, c'est pourquoi j'ai décidé de migrer mon blog et d'autres sites. Voici une vue d'ensemble du fonctionnement du blog dans Kubernetes, en sachant que le pod est composé d'un container OpenSMTPD (pour le formulaire de contact) et bien entendu d'un container Pluxml :
Note : Fait avec Diagrams (schema as code). L'Ingress Controller est Traefik (j'en parle plus bas).
Le changement n'a pas été instantané, loin de là, à vrai dire j'avais ce projet de côté depuis plus de 1 an. Mon idée de départ était de créer un cluster a plusieurs nœuds mais cela ajoute une contrainte au niveau du stockage, en effet il faut des volumes accessibles en réseau. La question des coût s'est posée également car mon blog n'est pas suffisamment important pour justifier 4 serveurs (3 noeuds + 1 NAS). J'ai donc fait des concessions et accepté d'utiliser un cluster Kubernetes à 1 nœud, avec la Storage Class par défaut de k3s (local-path). C'est donc un premier pas timide mais l'objectif est de me familiariser avec Kubernetes.
J'ai utilisé k3s, le Kubernetes Lightweight de Rancher. Cette distribution a l'avantage d'être facile à installer (une commande curl) et d'avoir une emprunte mémoire assez limitée (même si ça reste beaucoup plus élevé que Docker). Par contre elle n'est pas miraculeuse et le côté "lightweight" s'est fait en excluant ou limitant certaines features. Par exemple pour la gestion des Ingress on a droit à un Traefik built-in en version 1.7 (donc legacy) absolument pas documenté pour la gestion des certificats Let's Encrypt. J'ai donc désactivé cette version et installé le Traefik 2.x de containous grâce à Helm. Cette version de Traefik est implémentée en tant que CustomResourceDefinition (aka CRD) et est documentée sur le site officiel. J'avoue quand même avoir passé 3-4 jours à faire fonctionner ces satanés certificats Let's Encrypt mais j'y suis finalement parvenu et j'ai beaucoup appris.
Un autre point sur lequel k3s est limité est la liste de Storage Classes. Dans Kubernetes, une Storage Class, est en quelques sortes un driver qui peut provisionner à la volée des PersistentVolumes (PV). Dans mon cas je comptais utiliser AzureFiles pour provisionner des partages depuis un Storage account sur Azure mais il semble que k3s ne l'implémente pas. En lisant cette documentation je crois comprendre que k3s ne propose qu'une Storage Class locale, c'est à dire sur le nœud qui exécute le pod. Quand aux backends supportés, je ne trouve pas de liste même si j'ai pu valider que NFS fonctionne bien.
Migrer le blog dans Kubernetes m'a déjà permis d'apprendre beaucoup de choses. Rien de plus gratifiant que le sentiment "j'ai compris !!!" après avoir passé des heures à essayer en vain de faire fonctionner une ressource. J'espère me motiver un jour à ajouter d'autres nœuds dans mon cluster, quand j'aurai résolu le problème du stockage.