Ceph fait du stockage distribué. Il permet de répartir des données sur plusieurs machines avec réplicas, assurant ainsi une certaine sécurité et résilience.
Sauf que ça c'est la théorie, en pratique mon expérience a été assez mauvaise et non seulement source d'interruptions de service mais aussi d'un niveau de stress très important (jusqu'à ne plus dormir la nuit). Parce que oui perdre un serveur de prod n'est déjà pas agréable, mais quand il s'agit du stockage c'est encore pire.
Un admin qui bosse avec Ceph
Problème 1: l'usine à gaz
Ceph est gros, très gros, pour le compiler prévoyez au minimum 8GB de ram (sous peine de faire exploser votre machine) et plusieurs heures.
Ensuite pour être à l'aise prévoyez des machines bien dimensionnées (Xeon), beaucoup de RAM (1GB par TB) et du stockage SSD pour la journalisation. A l'usage ne vous étonnez pas de voir la RAM et la swap proche de la saturation, c'est le rythme de croisière.
Et puis l'architecture n'est pas simple il y a les OSD, les PGs, les différents services, et les logs parfois pas très clairs qui vous disent que la reconstruction est bloquée sans vraiment donner de raison.
Problème 2: les bugs
Sur la version Kraken (11.2) il existe une fuite de mémoire avec le service ceph-mgr. La solution est donc de le couper. Sauf que son rôle est justement de contrôler l'utilisation de la mémoire, donc le serveur va naturellement gonfler au fil des mois jusqu'à finir par exploser en vol. Il faut donc régulièrement lancer ceph-mgr puis le couper.
Le hic, c'est que dans le cas où votre serveur est déjà bien chargé (RAM + swap), le lancement de ceph-mgr ajoute un poids supplémentaire ce qui peut amener des lag sur le cluster le temps que la mémoire baisse... et ça c'est très mauvais. Dans mon cas cela a fait basculer plusieurs machines virtuelles en readonly.
Problème 3: ceph-deploy
Avec la mouvance devops il est de plus en plus courant de vouloir installer les choses sans devoir mettre les mains dans le cambouis, faire du sysadmin sans rien connaître en sysadmin quoi. Et c'est problématique. Certes c'est rapide et facile, mais en cas de panne on ne sait pas quoi faire car on ne sait pas comment marche le système.
Ceph-deploy fait le boulot à votre place, et dans le cas où ce n'est pas vous qui avez monté l'infra, si vous ne disposez pas du répertoire contenant les clés et la configuration, bon courage pour manipuler le cluster (ajout ou retrait de nodes). De plus ceph-deploy réserve des surprises en installant pas forcément la version qu'on lui demande...
Problème 4: les performances
Même avec un setup assez costaud (plein de RAM et de SSD) les I/O des VM qui sont stockées dessus sont décevantes. C'est un ressenti, mais à l'aire du SSD et/ou du stockage en RAID10, une installation d'une VM debian stockée sur cluster Ceph parait interminable.
Problème 5: résilience
Dans un cluster de 3 nodes on se dit qu'on est tranquilles car on peut en perdre 2 et continuer à fonctionner, un peu comme avec un RAID1 de 3 disques. Sauf qu'en pratique, il faut au minimum 2 nodes actives... Et oui, j'ai testé sur un cluster Ceph 0.96 et 11.2, dans les deux cas les données ne sont plus accessibles s'il ne reste qu'une seule node en vie.
Problème 6: targetcli
C'est le daemon iscsi de Ceph. Le problème ? Il perd sa conf partiellement ou totalement à chaque reboot. Prévoyez un targetctl restore systématique et un downtime possible si vous devez effectuer cette opération.
Conclusion: abandon
Alors que Ceph est censé apporter une continuité de service et donc un sérénité pour les admin, j'ai expérimenté le contraire. Les nombreux downtimes et les fois où j'ai été à deux doigts de perdre l'intégralité du stockage (et donc des machines virtuelles) m'ont causé des nuits blanches d'angoisse.
Les VM sont en cours de migration vers un SAN artisanal à base de Debian + iscsitarget. Il n'est peut-être redondé mais il est fiable, il n'y a pas de fuite de RAM, et s'il y a le moindre pépin nous connaissons les couches de A à Z pour pouvoir diagnostiquer.
En ce qui me concerne Ceph est une usine à gaz qui n'est pas production ready et j'espère ne plus avoir à y toucher de ma vie.
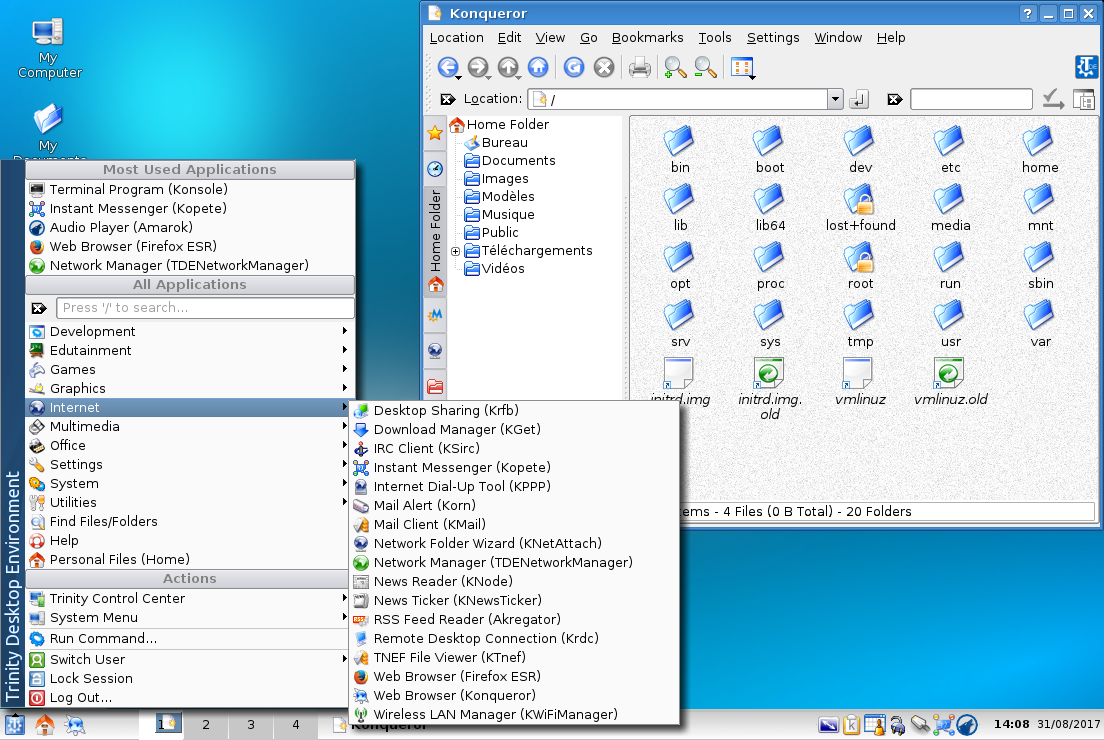
Pour la rigolage, installons Trinity Desktop, continuation de KDE3, sur Debian :
Ça fonctionne plutôt bien, les paquets ont été correctement renommés pour ne pas entrer en conflit avec ceux de KDE5, par exemple konqueror-trinity donc la cohabitation se passe bien. Cette capture d'écran nous rappelle à quel point KDE3 était une usine à gaz et un foutoir, avec un sous-menu "Internet" déjà saturé lors de l'installation ou encore la présence d'éléments redondants: est-il nécessaire d'avoir des sous-menu Settings, System, Utilities, Trinity Control Center, System Menu ? Naviguer dans mes fichiers avec Konqueror, c'est pas la joie, Dolphin (arrivé avec KDE4) est bien meilleur.
Il est amusant de noter que MATE, continuation de GNOME2 est un projet vivant et fournit dans quasiment toutes les distributions alors que TDE est clairement mal aimé. Le projet n'est certes pas abandonné mais aucune distribution ne l'intègre, probablement parce que la transition de KDE3 à KDE4 fut assez logique et naturelle pour les utilisateurs, contrairement à GNOME3.
Passer de KDE3 à KDE4 c'est un peu comme échanger le bureau de Windows XP par celui de Windows 7, certes on peut râler parce que c'est un peu plus lourd, mais c'est aussi plus moderne et surtout on l'utilise quasiment de la même façon, nos habitudes ne sont pas brisées.
Je suis curieux de savoir s'il y a des utilisateurs de TDE... si c'est le cas manifestez-vous ;)
Je lis parfois que l'environnement de bureau MATE va mourir parce qu'on ne peut pas faire vivre indéfiniment une vieille techno et parce qu'en face il y a KDE, GNOME et Cinamon qui sont beaucoup plus modernes, etc etc. Mais d'où vient cette idée ? Le projet est toujours vivant et si on en croit les notes de version de la 1.18, le portage vers GTK3 a même été terminé. Et puis qu'y a-t-il besoin de moderniser ? MATE est un fork de GNOME2 donc 15 ans d'expérience et de peaufinage, ça tourne au poil et il ne manque vraiment pas grand chose. Allez en cherchant on va dire que MATE supporte mal le hidpi mais je n'en ai pas besoin.
Après 11 ans d'utilisation de Linux les bureaux qui réinventent la roue sans arrêt me laissent de marbre. Regardons ce qu'on a en face de MATE :
GNOME3 et ses utilisateurs qui se masturbent sur les nouvelles fonctionnalités à chaque version même s'il ne s'agit que de réimplémentation de choses qui ont été supprimées avant parce que les développeurs ont décidé que c'était mieux pour vous.
KDE qui repart de zéro presque tous les ans mais subit les mêmes tares, qui considère que LTS = 1 an et qui s'en-tête à coder des milliers de logiciels que personne n'utilise : KMail, KOffice, Konqueror et la liste pourrait s'allonger.
LXDE déclaré mort au profil de LXQT. Sauf que LXQT c'est vraiment pas stable ni même proposé sur toutes les distributions contrairement à LXDE. C'est un environnement moins austère qu'il n'y parait et il constitue une bonne solution de secours quand même Xfce se révèle trop lourd pour votre machine.
Xfce dont on annonce la mort chaque année mais qui vit toujours. Il constitue une excellente alternative à MATE même si je regrette un peu le manque d'homogénéité des logiciels. Xubuntu est l'une des meilleures distributions desktop, à mon sens.
Ayant fait le tour des environnements j'en reviens toujours à MATE, Xfce et LXDE que je trouve stables, efficaces et léger. Leur ancienneté ne constitue pas une dette technique, un poids dont on essaie de se débarrasser, ils sont au contraire une solide base pour tous les vieux cons comme moi.
Si vous êtes familier avec l'écosystème des distributions Linux, vous avez probablement levé un sourcil (comme Teal'c) en lisant ce titre car vous les connaissez toutes, vous avez touché à tous les gestionnaires de paquet, vous avez utilisé debian et gentoo, en bref vous avez fait le tour et plus rien ne nous surprend.
Et pourtant, bien que NixOS soit une distribution assez ancienne (2003) elle dispose de nombreux atouts inédits passés plutôt inaperçus jusqu'à présent.
La configuration déclarative centralisée
Ce que je trouve le plus intéressant dans NixOS, c'est la configuration centralisée dans un unique fichier. En effet si vous avez déjà travaillé sur des routeurs ou diverses appliances, vous avez remarqué que l'on peut souvent importer et exporter la configuration sous forme de texte assez facilement, cela rend la maintenance très facile. Sous NixOS c'est le même principe, mais en plus puissant puisqu'on peut rollback voire booter sur une ancienne configuration depuis grub. Exemple de configuration d'un serveur MariaDB :
/etc/nixos/configuration.nix
{ config, pkgs, ... }:
{
imports =
[ # Include the results of the hardware scan.
./hardware-configuration.nix
];
# Use the systemd-boot EFI boot loader.
boot.loader.systemd-boot.enable = true;
boot.loader.efi.canTouchEfiVariables = true;
networking = {
hostName = "mariadb";
nameservers = [ "192.168.0.31" ];
defaultGateway = "192.168.0.254";
interfaces.enp0s3.ip4 = [
{
address = "192.168.0.41";
prefixLength = 24;
}
];
};
# Select internationalisation properties.
i18n = {
consoleFont = "Lat2-Terminus16";
consoleKeyMap = "fr";
defaultLocale = "fr_FR.UTF-8";
};
# Set your time zone.
time.timeZone = "Europe/Paris";
# List packages installed in system profile. To search by name, run:
# $ nix-env -qaP | grep wget
environment.systemPackages = with pkgs; [
git
htop
sudo
tree
vim
];
# Services
services = {
openssh = {
enable = true;
permitRootLogin = "yes";
};
mysql = {
enable = true;
package = pkgs.mysql;
extraOptions = ''bind-address=0.0.0.0'';
};
};
# Open ports in the firewall.
networking.firewall.allowedTCPPorts = [ 22 3306 ];
# networking.firewall.allowedUDPPorts = [ ... ];
# Define a user account. Don't forget to set a password with ‘passwd’.
users.extraUsers = {
utux = {
isNormalUser = true;
extraGroups = [ "wheel" ];
};
};
# The NixOS release to be compatible with for stateful data such as databases.
system.stateVersion = "17.03";
}
/etc/nixos/hardware-configuration.nix
# Do not modify this file! It was generated by ‘nixos-generate-config’
# and may be overwritten by future invocations. Please make changes
# to /etc/nixos/configuration.nix instead.
{ config, lib, pkgs, ... }:
{
imports = [ ];
boot.initrd.availableKernelModules = [ "virtio_pci" "ahci" "xhci_pci" "sr_mod" "virtio_blk" ];
boot.kernelModules = [ ];
boot.extraModulePackages = [ ];
fileSystems."/" =
{ device = "/dev/disk/by-uuid/78634ba0-11d1-4f91-85ae-ac2ee247c387";
fsType = "xfs";
};
fileSystems."/boot" =
{ device = "/dev/disk/by-uuid/019A-1A05";
fsType = "vfat";
};
swapDevices =
[ { device = "/dev/disk/by-uuid/075a27eb-5656-4b57-b186-73a6d86e5e5c"; }
];
nix.maxJobs = lib.mkDefault 1;
}
Comme vous le voyez, le fichier configuration.nix contient toute la configuration, incluant les services tiers tels que mariadb dans notre cas. Cela va donc encore plus loin que le /etc/rc.conf sur FreeBSD/NetBSD/OpenBSD qui centralise déjà pas mal de choses. Le fichier hardware-configuration.nix lui est généré automatiquement il n'y a pas besoin d'y toucher et il est plus ou moins unique par serveur.
Pour générer et appliquer la configuration :
nixos-rebuild switch
Pour mettre à jour le système :
nixos-rebuild switch --upgrade
Puis un petit mysql_secure_installation la première fois pour préparer notre SGBD.
Ce qu'il reste à faire en dehors du configuration.nix, c'est la définition des mots de passe, avec passwd et bien sûr la gestion des données persistantes (les bases de données pour mariadb par exemple).
Nix, gestionnaire de paquets fonctionnel
Je vais être un peu plus prudent sur ce point, car étant encore en phase de découverte de NixOS, je ne connais pas encore très bien le gestionnaire de paquets Nix. Cependant, à la différence des gestionnaires classiques tels que apt, yum ou pacman, il ne se contente pas d'aller chercher des paquets pour les décompresser. Chaque version de chaque paquet est installé dans une arborescence /nix/store/{identifiant unique}, du coup plusieurs versions peuvent cohabiter ensemble et les mises à jour n'écrasent rien. Il est possible également pour les utilisateurs d'installer des paquets pour leur environnement (non-root) uniquement.
Mon avis
J'ai mis un serveur NixOS en test et il est trop tôt pour en tirer des conclusions. Mais j'aime l'idée de configuration centralisée déclarative, car la configuration classique des systèmes Linux n'est pas toujours simple à maintenir : Docker, Ansible, NixOS : le savoir (re)faire.
Si je dois citer deux inconvénients à NixOS : elle prend de la place (1,6GB à l'installation avec MariaDB) et elle nécessite au moins 1GB de RAM pour s'installer sous peine de voir oomkiller tuer nixos-install... elle peut cependant tourner avec 256MB par la suite.
NixOS nous montre qu'une distribution Linux ce n'est pas seulement un éinième fork de Ubuntu avec un wallpaper personalisé, ou encore une guerre de gestionnaire de paquets (dnf/apt), il existe encore de l'innovation et rien que pour cela elle mérite le coup d’œil.
Note : si /media/cdrom est vide, essayez d'ouvrir le CD-ROM VBOXADDITIONS apparu sur votre bureau ou dans votre gestionnaire de fichiers (selon l'environnement). Vous pouvez aussi essayer la commande suivante :
$ sudo mount cdrom
Pensez à redémarrer la machine virtuelle.
Résumé :
build-essential : Méta-paquet qui installe les outils nécessaires à la compilation, c'est la boîte à outils de base pour Debian.
dkms : Framework qui permet de compiler des modules pour le noyau. Non seulement c'est plus propre qu'un make install (automatisation et suivi des versions) mais aussi et surtout il recompilera automatiquement les modules en cas de mise à jour du kernel.