Avec beaucoup de retard, et alors que la mini-série Obi-Wan Kenobi démarre demain, je livre un court avis sur The book of Boba Fett que j'ai vu il y a quelques mois.
Alors que Disney a bien failli tuer la licence Star Wars avec sa postlogie misérable et inutile, force est de constater qu'ils s'en sortent beaucoup mieux au niveau des séries. Je dirais même qu'ils lui ont redonné un nouveau souffle avec The Mandalorian et que cela fait beaucoup de bien.
Malheureusement, les retours sur The book of Boba Fett sont beaucoup moins élogieux, ils sont même très partagés, parfois décevants. Mais si j'écris cet article c'est avant pour tout pour donner mon propre avis complètement subjectif.
Au tout début, la série m'a vraiment emballé. Même si je dois admettre que le personnage de Boba Fett en lui-même n'était pas passionnant, j'étais vraiment attiré par tout ce qu'il y avait autour. La ville de Mos Espa, le palais de Jabba le Hut, le Saarlacc... j'avais l'impression de voir un fork du début de Star Wars Episode VI, et je trouvais intéressant de mettre de côté les Jedi, la force, le bien et le mal, pour faire place à un bon petit western. La série introduisait de nombreux personnages, des intrigues politiques, des enjeux, du fan service (le chasseur Naboo), l'histoire des hommes des sables, bref le parfait cocktail pour attiser mon intérêt. Et là, c'est le drame.
C'est le drame oui, car au fur et à mesure des épisodes, les intrigues et les personnages ne sont jamais développés, ne mènent nulle part ou ne servent à rien. Boba Fett est... un gentil. On comprend rapidement que sa motivation pour prendre la suite de Jabba et devenir un seigneur du crime, est de faire le bien, c'est tout. Fennec ne sert à rien, 90% des personnages introduits dans les premiers épisodes passeront à la trappe. Et puis il y a l'épisode de trop.
La série décide en plein milieu de revenir sur les aventures du Mandalorien, comme si elle oubliait qu'elle était censée raconter l'histoire de Boba Fett, mais il y a pire. Pire oui, car un des épisodes remet à l'honneur Grogou et Luke Skywalker.
L'apparition de Luke Skywalker en Deus Ex Machina à la fin du Mandalorian était un moment épique qui a fait couler pas mal de larmes des yeux des fan. Mais la séquence était courte et se suffisait à elle-même, le personnage n'avait pas vraiment de dialogue, c'était presque un caméo, il n'en fallait pas plus. Or la série Boba Fett nous offre un épisode complet où Luke en CGI réapparaît, a des dialogues, et nous montre qu'il est devenu un Jedi chiant et dogmatique comme ceux de la prélogie. C'était vraiment l'épisode de trop, foutez la paix à Luke Skywalker, laissez ce personnage vivre dans le cœur des fans, n'essayez pas de lui écrire une nouvelle histoire, ça ne marche pas.
Alors que mon intérêt pour cette série était au plus bas et que je songeais même à arrêter de regarder, la fin se profilait déjà à l'horizon. Et même si elle confirme qu'aucune intrigue, aucun personnage n'a d'importance dans la série, elle a le mérite de nous offrir une ultime bataille divertissante. Finalement mon intérêt pour cette série aura été une courbe en parabole, c'est à dire en forme de U, mais cela n'aura pas suffit à me convaincre.
Pour conclure, je ne peux que me ranger à l'avis général: The Book of Boba Fett était une série décevante qui souffrait de gros problèmes d'écriture. Je reproche à la postlogie d'être faite par des gens qui ne connaissent rien à Star Wars, The Book of Boba Fett en est un peu l'antimatière: elle a été faite par des gens qui connaissent très bien Star Wars, mais qui ont échoué à écrire une histoire consistante.
Je compte beaucoup sur la série Obi-Wan Kenobi pour relever le niveau, et je serais devant mon PC le 27 Mai.
C'est une mauvaise décision, et je vais essayer d'exprimer mon point de vue sans parler de Cancel culture car d'une part ce n'est pas mon intention, et d'autre part je pense que le but n'est pas réellement de protéger les créateurs, mais les intérêts des partenaires.
Tout d'abord, YouTube semble amalgamer les pouces rouges avec le harcèlement. S'il est vrai qu'une vague massive de dislikes peuvent avoir pour objectif de porter atteinte à une personne ou à une marque (voir Review bomb), c'est un phénomène très marginal, et plutôt dirigé envers les entreprises. Sony en a fait les frais avec son trailer Ghostbusters 2016 ou avec la première version du design de Sonic the Hedgehog sorti en 2020.
Ensuite, si le but est vraiment de protéger les créateurs du harcèlement, alors je pense que c'est une mauvaise décision, car sans le compteur de dislikes, les spectateurs iront poster des commentaires à la place pour exprimer leur opinion. A mon sens, un commentaire agressif est infiniment plus blessant qu'un pouce rouge. Et le pire dans tout cela, c'est que les créateurs voient toujours les dislikes dans leurs statistiques, ils ne sont justes plus affichés publiquement, donc le prétexte tombe complètement à plat.
Je ne considère pas les dislikes comme un outil de harcèlement, le but est simplement de donner un avis sur la qualité d'une vidéo, c'est une sorte de vote, et c'est très utile. Par exemple lorsque je recherche des tutoriels pour du bricolage, la note de la vidéo me permet de voir si l'auteur dispense de bonnes pratiques, ou si au contraire il n'y connaît pas grand chose. C'est donc pour moi une fonctionnalité importante de la plateforme qui disparaît.
Au final cette décision est une fausse solution à un problème qui n'en est pas un. La plateforme est gangrenée par des problèmes bien plus graves, en premier plan la rémunération des vidéastes. Si vous voyez de la publicité pour NordVPN ou RAID Shadow Legends dans toutes les vidéo, c'est parce qu'il est devenu quasi impossible d'être rémunéré par YouTube. Fred de l'émission Joueur du Grenierexplique par exemple que le simple fait d'avoir utilisé "le rire" de Michael Jackson (Thriller) a suffit pour Claim une de leurs vidéos. Le Claim, c'est quand un ayant droit s’accapare la totalité de la rémunération de votre vidéo, sous prétexte que vous utilisez un élément soumis aux droits d'auteurs. Même si vous utilisez un extrait qui dure 2 secondes, même si la loi française l'autorise (exceptions au droit d'auteur), c'est une entreprise qui touchera la totalité des revenus de la vidéo pour laquelle vous avez travaillé.
Pour conclure, cette décision unilatérale de retirer l'affichage des Dislikes est représentative de la politique désastreuse de la plateforme. Si vous voulez protester :
Installez uBlock Origin, coupez les vannes de la publicité qui ne sert qu'à rémunérer les ayants droits. Les vidéastes ne touchent déjà plus rien de toutes manières.
Demandez à vos vidéastes préférés d'aller sur d'autres plateformes, au moins en secondaire. Ils se plaignent sans arrêt de Youtube mais refusent d'aller voir ailleurs, par peur de perdre des vues ou de froisser leurs sponsors. Motivez-les.
Et c'est malheureusement tout ce que nous pouvons faire pour le moment. La plateforme jouit d'un monopole complet et n'a aucune concurrence. La télévision 3.0 est déjà là, et ce n'est pas une bonne chose.
EDIT: grâce à l'extension "Return YouTube Dislike" on peut voir le vrai score de l'annonce officielle au 05/12/2021, et ça montre à quel point les utilisateurs sont mécontents :
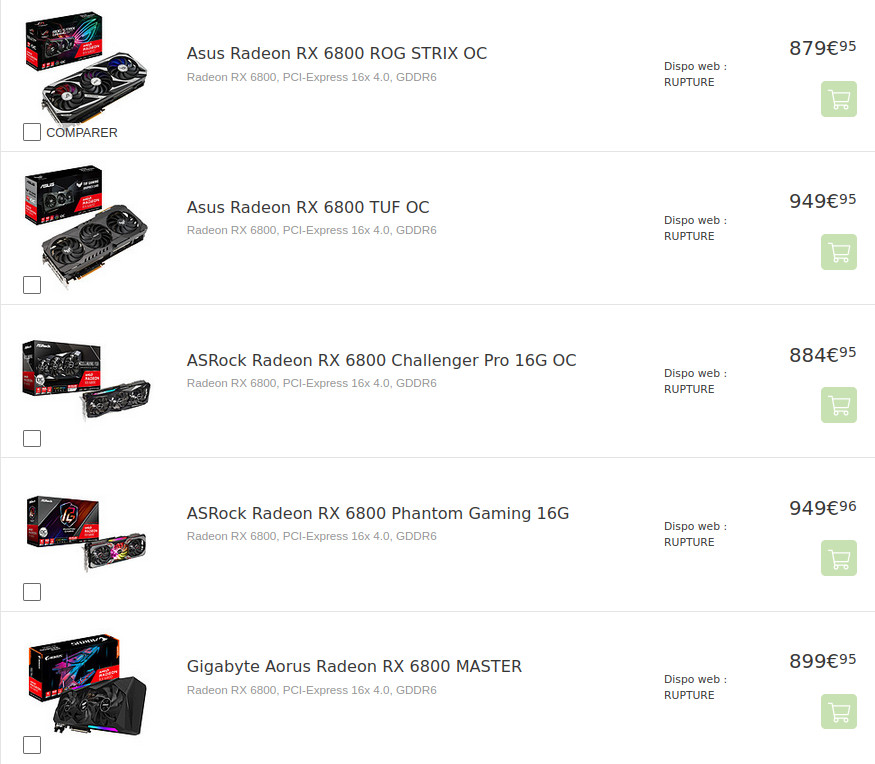
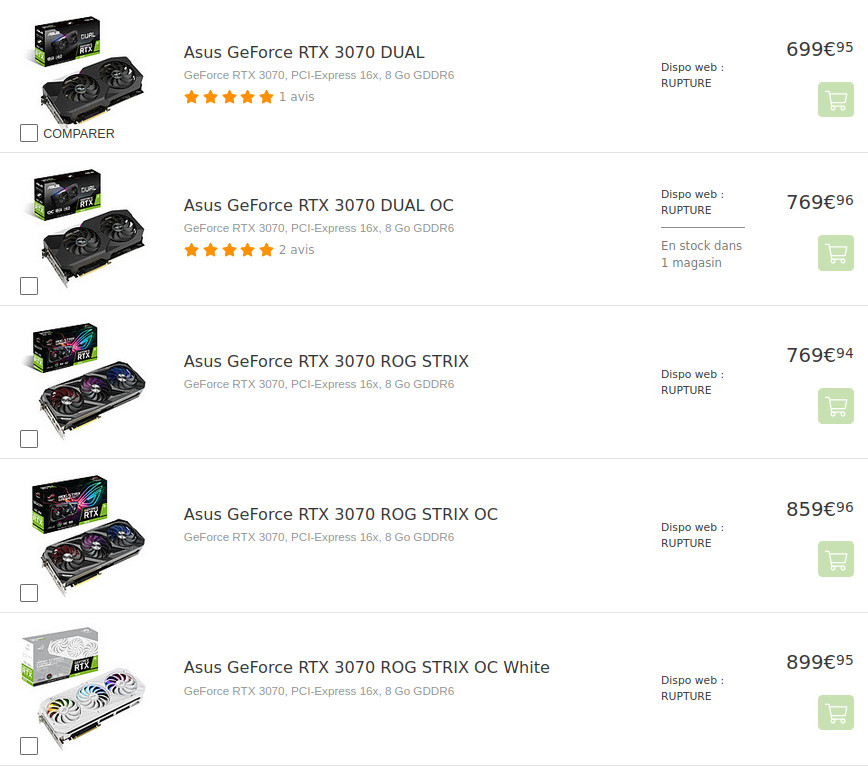
Si vous ne suivez pas l'actualité du hardware, sachez que fin 2020 / début 2021 il est extrêmement difficile d'acheter des cartes graphiques, il y a une grosse pénurie sur à peu près tous les modèles :
Les cartes AMD chez materiel.net
Ou encore :
Les cartes Nvidia chez materiel.net
La cause de cette pénurie généralisée est difficile à identifier, beaucoup d'explications sont avancées sans preuve donc je ne les relaierai pas ici, mais disons que la sortie concurrente des AMD / Nvidia / Xbox Series / PS5 provoque des problèmes d'approvisionnement sur certaines puces. Cette énorme demande a provoqué l'explosion des prix des rares modèles disponibles d'autant plus qu'un phénomène de spéculation s'est créé (des gens achètent en masse des cartes pour les revendre sur eBay à prix d'or).
Les seules cartes qui sont restées à un prix fixe et "raisonnable" sont les "Founder Edition" (modèles vendus directement par Nvidia ou AMD). Le hic c'est qu'elles sont elles aussi en rupture de stock et qu'à chaque réapprovisionnement tout s'évapore en 2 minutes chrono ! Nous sommes donc rendus dans une situation où il faut utiliser des services de notification en temps réel et avoir un PC à portée de main pour avoir un espoir de commander. Et c'est ce que j'ai utilisé.
Je dois remercier pour cela FE PartAlert (et ses notifications Push dans Telegram) pour m'avoir sauvé la mise. A 14h40 j'ai reçu une notification, j'ai commandé (avec plusieurs refresh car le site avait du mal), et à 14h52 tout était déjà épuisé. Ce réapprovisionnement du catalogue (ou "drop" pour les initiés) aura donc tenu 12 minutes, un record.
Au final j'ai donc réussi à commander une RTX 3070 FE au prix officiel Nvidia (€519) qui pourra remplacer ma vénérable GTX 1070 que je possède depuis maintenant 4 ans. J'étais aussi très intéressé par une AMD RX 6800, mais les drop sont encore plus rares.
Le marché des cartes graphiques est vraiment dans un état lamentable. Entre la pénurie, la spéculation et les tarifs applesques, il est de plus en plus tentant de regarder du côté des nouvelles consoles (Xbox Series / PS5) ou des offres gaming cloud qui sont beaucoup plus abordables. L'avenir nous dira si le gaming PC "pur" est en train de se limiter petit à petit à une élite (très) fortunée capable de claquer €1000 dans une carte graphique.
La nouvelle est tombée il y a quelques jours : le support de CentOS 8 se terminera fin 2021 et la distribution basculera à 100% sur le modèle Stream. C'est un changement de gouvernance brutal et destructeur pour ses utilisateurs car CentOS ne sera plus un clone de Red Hat gratuit mais plutôt son pendant "Windows Insider".
Il faut bien comprendre que CentOS c'est quelque chose de gros : c'est la 2e distribution la plus utilisée au monde sur les serveurs Web Linux en 2020 avec 18,8% de parts de marché. Moi qui travaille avec du Cloud et du Linux en entreprise, je confirme que ça représente à la louche 60% de nos serveurs (non Windows) peut-être même plus.
Qu'est-ce qui plaît autant dans cette distribution encore plus en retard que Debian et avec des dépôts tellement vides qu'il n'y a ni nginx ni htop ?
C'est basiquement un clone gratuit de Red Hat, donc très stable et certifiée par des tas de constructeurs de matériel et éditeurs de middlewares.
Support incroyablement long, une dizaine d'années.
Bénéficie de l'énorme documentation en ligne de Red Hat.
La pauvreté des dépôts est compensée par EPEL et SCL (mais aussi tout un tas d'autres).
La version du kernel est vieille mais les drivers et correctifs de sécurité sont backportés dedans.
Certains n'aiment pas les libertés prises par Debian dans le packaging de certaines applications (par exemple Apache). CentOS est un peu plus proche de l'upstream sur ce point.
En gros CentOS était une distribution incassable, prévisible, ennuyeuse, et avec un support extrêmement long. On comprend alors que l'abandon de cette stabilité au profil d'un modèle de type "testing" ou "insider" va totalement à l'encontre de ce qui faisait son intérêt. Mais alors, que peut-on faire ?
Si possible, ne plus déployer de CentOS 8 en attendant que la situation se stabilise. Cette annonce a provoqué de très nombreux retours négatifs de la communauté et il est évident que le projet se rend compte qu'il se saborde lui-même. En ce qui me concerne j'espère soit une annulation de cette décision, soit au contraire un message clair qui indique qu'IBM/Red Hat ne veut plus de CentOS dans sa forme actuelle, dans les deux cas nous serions fixés sur l'avenir.
En attendant, si vous devez déployer de nouveaux serveurs, il existe des alternatives :
Si vous n'avez aucune fidélité à RHEL/CentOS ou aux RPMs, Debian et Ubuntu sont des alternatives de choix. J'ai une nette préférence pour la première que j'ai toujours trouvé plus légère, plus stable, et qui n'installe pas snap par défaut.
CentOS 7 reste une option à ne pas négliger, car supportée jusqu'en 2024.
Si vous avez besoin de la compatibilité RHEL/CentOS 8, il y a Oracle Linux. Alors oui le nom fait peur car quand on parle d'Oracle on pense aux tarifs exorbitants, à OpenOffice, et aux pratiques crapuleuses, il n'empêche que la distribution est bien gratuite et qu'elle perdure depuis 2013, en plus d'être elle aussi un clone de Red Hat. Elle est fournie avec deux kernel : RHCK (compatible Red Hat / CentOS) et UEK (Unbreakable Enterprise Kernel, plus récent et ne nécessitant pas de reboot). Oracle Linux est à mon sens l'alternative la plus crédible à CentOS. Pour couronner le tout, un script de migration est disponible : lien vers un retour d'expérience.
Je ne recommande pas Rocky Linux, c'est beaucoup trop tôt. Des tas de distributions naissent et meurent chaque année, ou se retrouvent parfois dans un état intermédiaire façon Mageia, donc attendons de voir si Rocky aura les moyens de ses ambitions. Elle n'est de toutes manières pas encore disponible.
Il est urgent d'attendre, laissez passer les fêtes pour voir comment la situation évolue. Voilà mon avis sur le feuilleton CentOS ;)
Je me suis inscrit assez tard sur Facebook - début 2018 - et l'expérience aura duré un peu moins de 3 ans.
Les raisons qui m'ont poussé à me désinscrire :
C'est con, mais le problème des réseaux sociaux est qu'il y a d'autres gens et rares sont ceux qui ont des choses intéressantes à dire, surtout en cette période anxiogène où la mode est aux complots et aux critiques en tous genres. Je me suis rendu compte que j'avais fini par masquer quasiment tous mes contacts pour ne plus voir leurs publications. C'est la raison la plus importante de mon départ.
Un peu le même problème que Diaspora à savoir une présentation qui ne tire pas parti des écrans larges et oblige à scroller en permanence. L'ergonomie est misérable puisque personnellement j'ai toujours eu énormément de mal à retrouver des posts un peu vieux, je ne comprends rien à la manière dont le fil d'actus est trié.
Des problèmes de performances, avec tout d'abord un site lourd et peu réactif mais aussi des temps de chargements trop important des ressources statiques (comme les images). Je rencontre aussi un bug avec Firefox ESR qui rend l'outil de messagerie instantané quasiment inutilisable, m'obligeant à passer sous Chrome.
La publicité. Que ce soit pour un jeu free to play débile ou encore une grande enseigne de supermarché qui vous rappelle l'importance d'acheter des produits locaux et naturels, non merci.
Le matraquage de messages du gouvernement, par rapport au port du masque par exemple. Je n'ai rien contre, mais on y a droit à la télé, à la radio, dans les rues, dans les entreprises, sur youbube, dans les discussions avec les proches... c'est bon on a compris, stop. Si j'ai envie de me ronger les ongles devant un compteur de morts du COVID je peux aussi allumer BFMTV (ou lire n'importe quel journal).
Pour en dire du positif :
Les communautés, assez complémentaires des forums. Si par exemple vous êtes un passionné d'informatique vintage, il y a de très nombreux groupes où discuter et poser des questions.
Trouver des gens. En tant que réseau social le plus populaire c'est ici que vous pourrez renouer contact avec d'anciens amis, collègues ou camarades.
Les pages des magasins, boutiques et associations. Pour ceux qui n'ont pas l'envie ou les moyens de faire un site Internet, Facebook est un bon backup.
Il n'est pas exclu que je revienne un jour, si le service évolue en bien.