J'adore gitlab, alternative libre à github installable chez soi ou utilisable en tant que service. Il a énormément de fonctionnalités: gestion du https avec letsencrypt, embarque sa BDD Postgresql, du CI avec des runnners, des issues, un registry Docker, et même de la métrologie... le tout avec une interface graphique intuitive et bien léchée.
Le problème de gitlab, c'est qu'il est monolithique et gourmand. Trop gourmand. J'ai installé une instance de gitlab-ce sur un serveur équipé de 2G de RAM, et au bout de quelques jours des erreurs 502 sont apparues. En me connectant sur le serveur j'ai constaté qu'il était quasi saturé: 1,7G ! Et en effet, après avoir consulté la page des requirements, j'a rapidement compris. Le minimum du minimum, c'est 4G de RAM + 4G de swap! Et la recommandation est de 8G!
Pour un usage perso, il est quand même ennuyeux de devoir louer un VPS à 8G de RAM, c'est pas donné, on tape dans la dizaine d'euros par mois voire plus. J'ai essayé quelques optimisations, comme diminuer le nombre de workers, le cache Postgresql, la métrologie... et après un redémarrage je suis à 1,5G de RAM.
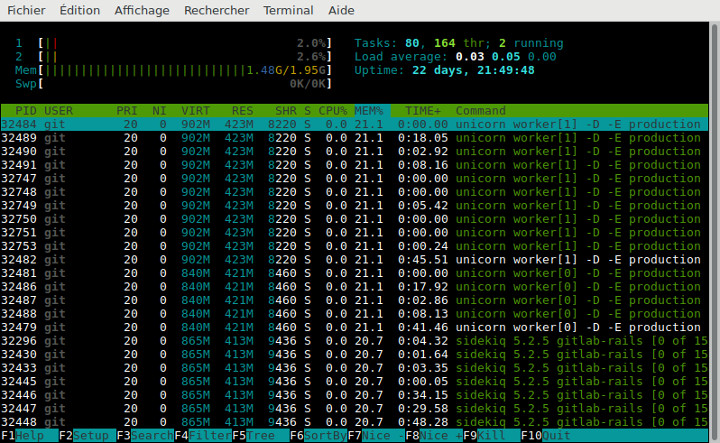
Moui, ce n'est pas une franche réussite. Au moindre pic de consommation le serveur va ookill des processus. Gitlab est cool mais c'est un peu une usine à gaz en terme de ressources.
Même si je suis toujours fan de Gitlab et le recommande pour les entreprises et les organisations, je vais me mettre en recherche d'une alternative plus propice aux usages persos.
Vous avez tous eu dans votre entreprise un serveur nommé Orion car le nommage selon les constellations ou objets du système solaire est un grand classique. J'ai eu affaire à du Asterix et Obelix, Tom et Jerry, Arnold et Willy... et je trouve ça pénible. Beaucoup de gens choisissent un dictionnaire bien précis pour nommer leur serveur, il y en a d'ailleurs une liste ici, et pourtant je ne pense pas que ce soit une bonne pratique. Outre le fait que nous n'avons pas forcément le même humour que nos prédécesseurs, cela peut vite devenir l'enfer dans les situations d'urgence:
At 3am, when the world is burning down, having to figure out if "tatooine" is the DNS or the DHCP server is a problem you DON'T want or need.
Source.
Il est plus avisé de choisir un nom qui donne des informations utiles, comme la localisation et la fonction, ou encore le client quand il s'agit d’infogérance. Je n'ai pas encore trouvé la solution idéale, mais je trouve cet article intéressant: A Proper Server Naming Scheme. Le début me contredit puisqu'il recommande de donner des noms sans rapport avec la fonction et d'utiliser ensuite des CNAME records, mais je le trouve quand même assez complet. Ainsi pour un hypothétique serveur Web utux de développement hébergé à Amsterdam et faisant partie de l'organisation utux.fr on obtient ça:
On a toutes les infos dont on a besoin en un simple coup d'oeil. L'inconvénient est que c'est un peu long pour un hostname ou un nom de machine virtuelle. Je ne gère que mes propres serveurs et je n'en ai pas une centaine, j'ai donc plutôt adopté ce format:
Simple, efficace et lisible. Et vous?
Sources:
I want to generate a /usr/local/etc/backuppc/hosts with all hosts from the ansible inventory, but exclude a group.
Inventory:
[dbservers]
db1
db2
db3
[DisableBackup]
db3
hosts.j2:
# {{ ansible_managed }}
{% for hosts in groups['all'] | difference(groups['DisableBackup']) %}
{{ hosts }}
{% endfor %}
tasks/generate_hosts.yml:
- name: Generate hosts file
template:
src: hosts.j2
dest: "{{ backuppc__confdir }}/hosts"
owner: "{{ backuppc__user }}"
group: "{{ backuppc__group }}"
mode: 0644
force: yes
Run:
ansible-playbook -i inventory install_backuppc.yml
Result:
cat /usr/local/etc/backuppc/hosts
# Ansible managed
db1
db2
Source.
Essayons de désactiver AppArmor sur une Ubuntu 16.04 en nous basant sur la documentation.
C'est pourtant clair, 3 sources de documentations nous disent que pour désactiver AppArmor il suffit de stopper le service. Très bien, essayons:
root@ubuntu:~# systemctl stop apparmor
root@ubuntu:~# systemctl disable apparmor
apparmor.service is not a native service, redirecting to systemd-sysv-install
Executing /lib/systemd/systemd-sysv-install disable apparmor
insserv: warning: current start runlevel(s) (empty) of script `apparmor' overrides LSB defaults (S).
insserv: warning: current stop runlevel(s) (S) of script `apparmor' overrides LSB defaults (empty).
Utilisons la commande apparmor_status pour voir le status de AppArmor:
root@ubuntu:~# apparmor_status
apparmor module is loaded.
13 profiles are loaded.
13 profiles are in enforce mode.
/sbin/dhclient
/usr/bin/lxc-start
/usr/lib/NetworkManager/nm-dhcp-client.action
/usr/lib/NetworkManager/nm-dhcp-helper
/usr/lib/connman/scripts/dhclient-script
/usr/lib/lxd/lxd-bridge-proxy
/usr/lib/snapd/snap-confine
/usr/lib/snapd/snap-confine//mount-namespace-capture-helper
/usr/sbin/tcpdump
lxc-container-default
lxc-container-default-cgns
lxc-container-default-with-mounting
lxc-container-default-with-nesting
0 profiles are in complain mode.
1 processes have profiles defined.
1 processes are in enforce mode.
/sbin/dhclient (848)
0 processes are in complain mode.
0 processes are unconfined but have a profile defined.
Diantre! C'est pas bon signe. Faisons un essai en installant mysql-server et en déplaçant son /var/lib/mysql ailleurs:
root@ubuntu:~# apt-get install mysql-server
root@ubuntu:~# systemctl stop mysql
root@ubuntu:~# mv /var/lib/mysql /opt/
root@ubuntu:~# sed -i "s@/var/lib/mysql@/opt/mysql@g" /etc/mysql/mysql.conf.d/mysqld.cnf
root@ubuntu:~# systemctl start mysql
Job for mysql.service failed because the control process exited with error code. See "systemctl status mysql.service" and "journalctl -xe" for details.
Mysql ne démarre pas... examinons le log:
juil. 07 10:39:37 ubuntu kernel: audit: type=1400 audit(1530952777.364:32): apparmor="DENIED" operation="open" profile="/usr/sbin/mysqld" name="/opt/mysql/ibdata1" pid=2959 comm="mysqld" requested_mask="wr" denied_mask="w
juil. 07 10:39:37 ubuntu systemd[1]: mysql.service: Main process exited, code=exited, status=1/FAILURE

AppArmor n'est pas désactivé du tout, on ne peut pas faire confiance à la documentation Ubuntu!!! Il faut en fait rebooter le serveur, vraiment génial quand celui-ci est déjà en production ou quand on essaie d'automatiser une installation avec Ansible.
Après quelques recherches je suis tombé sur cet article qui nous indique qu'on peut utiliser la commande service apparmor teardown :
root@ubuntu:~# service apparmor teardown
* Unloading AppArmor profiles [ OK ]
root@ubuntu:~# apparmor_status
apparmor module is loaded.
0 profiles are loaded.
0 profiles are in enforce mode.
0 profiles are in complain mode.
0 processes have profiles defined.
0 processes are in enforce mode.
0 processes are in complain mode.
0 processes are unconfined but have a profile defined.
root@ubuntu:~# systemctl start mysql
root@ubuntu:~# ps aux | grep mysql
mysql 925 0.0 13.2 1107628 134140 ? Ssl 10:43 0:00 /usr/sbin/mysqld
root 1224 0.0 0.0 14264 920 pts/0 S+ 10:46 0:00 grep --color=auto mysql
AppArmor nous laisse enfin tranquille, et sans rebooter le serveur :)
De manière amusant, teardown se traduit par démolir, raser. Est-ce une indication de l'état d'esprit de celui qui a codé le service de démarrage/arrêt d'AppArmor?
Je suis de moins en moins fan de Ubuntu sur les serveurs, car entre les très nombreuses mise à jour de Kernel (reboot fréquents) et les technologies maison de Canonical qui imite RedHat sans en avoir les moyens ou le talent, on se dit que rien ne vaut Debian ou CentOS sur un serveur.
Wow, on parle souvent des smartphones impossibles à démonter, en ce qui concerne le serveur HP Proliant Gen8 c'est totalement l'inverse, tout se fait sans tournevis de manière évidente. On ouvre le boîtier, on débranche les connecteurs sur la carte mère, et on la tire vers l'arrière, et voilà.
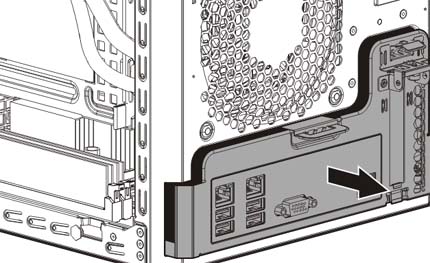
Une fois la carte mère extraite, il ne reste plus qu'à retirer le radiateur, enlever le Celeron puis insérer le Xeon, et après un petit changement de pâte thermique on remet le tout. Et au boot... ça marche !!
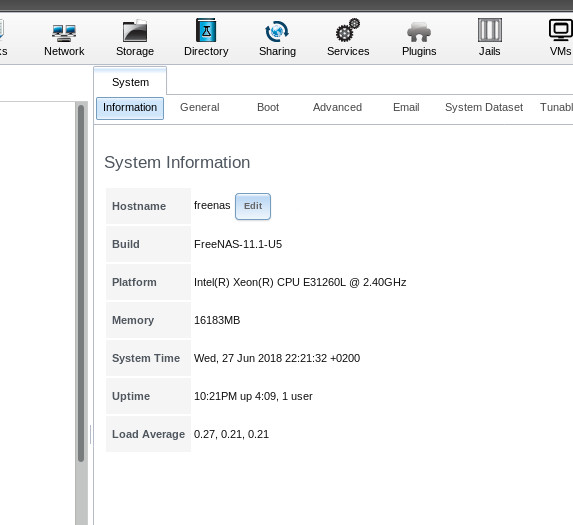
Le Xeon apporte un certain confort qui se ressent rapidement. L'exploration des partages Samba est plus fluide tout comme la navigation dans l'interface FreeNAS. Le démarrage des jails iocage aussi, même si non exempt de latences tant que le cache ARC n'est pas rempli :) Quand le prix des SSD de 1To baissera, je songerai à remplacer les disques mécaniques.