La nouvelle est tombée il y a quelques jours : le support de CentOS 8 se terminera fin 2021 et la distribution basculera à 100% sur le modèle Stream. C'est un changement de gouvernance brutal et destructeur pour ses utilisateurs car CentOS ne sera plus un clone de Red Hat gratuit mais plutôt son pendant "Windows Insider".
Il faut bien comprendre que CentOS c'est quelque chose de gros : c'est la 2e distribution la plus utilisée au monde sur les serveurs Web Linux en 2020 avec 18,8% de parts de marché. Moi qui travaille avec du Cloud et du Linux en entreprise, je confirme que ça représente à la louche 60% de nos serveurs (non Windows) peut-être même plus.
Qu'est-ce qui plaît autant dans cette distribution encore plus en retard que Debian et avec des dépôts tellement vides qu'il n'y a ni nginx ni htop ?
C'est basiquement un clone gratuit de Red Hat, donc très stable et certifiée par des tas de constructeurs de matériel et éditeurs de middlewares.
Support incroyablement long, une dizaine d'années.
Bénéficie de l'énorme documentation en ligne de Red Hat.
La pauvreté des dépôts est compensée par EPEL et SCL (mais aussi tout un tas d'autres).
La version du kernel est vieille mais les drivers et correctifs de sécurité sont backportés dedans.
Certains n'aiment pas les libertés prises par Debian dans le packaging de certaines applications (par exemple Apache). CentOS est un peu plus proche de l'upstream sur ce point.
En gros CentOS était une distribution incassable, prévisible, ennuyeuse, et avec un support extrêmement long. On comprend alors que l'abandon de cette stabilité au profil d'un modèle de type "testing" ou "insider" va totalement à l'encontre de ce qui faisait son intérêt. Mais alors, que peut-on faire ?
Si possible, ne plus déployer de CentOS 8 en attendant que la situation se stabilise. Cette annonce a provoqué de très nombreux retours négatifs de la communauté et il est évident que le projet se rend compte qu'il se saborde lui-même. En ce qui me concerne j'espère soit une annulation de cette décision, soit au contraire un message clair qui indique qu'IBM/Red Hat ne veut plus de CentOS dans sa forme actuelle, dans les deux cas nous serions fixés sur l'avenir.
En attendant, si vous devez déployer de nouveaux serveurs, il existe des alternatives :
Si vous n'avez aucune fidélité à RHEL/CentOS ou aux RPMs, Debian et Ubuntu sont des alternatives de choix. J'ai une nette préférence pour la première que j'ai toujours trouvé plus légère, plus stable, et qui n'installe pas snap par défaut.
CentOS 7 reste une option à ne pas négliger, car supportée jusqu'en 2024.
Si vous avez besoin de la compatibilité RHEL/CentOS 8, il y a Oracle Linux. Alors oui le nom fait peur car quand on parle d'Oracle on pense aux tarifs exorbitants, à OpenOffice, et aux pratiques crapuleuses, il n'empêche que la distribution est bien gratuite et qu'elle perdure depuis 2013, en plus d'être elle aussi un clone de Red Hat. Elle est fournie avec deux kernel : RHCK (compatible Red Hat / CentOS) et UEK (Unbreakable Enterprise Kernel, plus récent et ne nécessitant pas de reboot). Oracle Linux est à mon sens l'alternative la plus crédible à CentOS. Pour couronner le tout, un script de migration est disponible : lien vers un retour d'expérience.
Je ne recommande pas Rocky Linux, c'est beaucoup trop tôt. Des tas de distributions naissent et meurent chaque année, ou se retrouvent parfois dans un état intermédiaire façon Mageia, donc attendons de voir si Rocky aura les moyens de ses ambitions. Elle n'est de toutes manières pas encore disponible.
Il est urgent d'attendre, laissez passer les fêtes pour voir comment la situation évolue. Voilà mon avis sur le feuilleton CentOS ;)
I need to backup my NAS to a remote and secured location, and because I am a Azure AZ-103 associate, I have decided to use an Azure storage account. I will use Duplicati, a free backup software written in C# with the following features:
Storage account offers 3 tier with different pricing: hot, cool, archive. If you choose a hot tier, access is less charged, but storage is more expensive. This is the opposite for cool and archive, storage is cheap but access is expensive. Archive is the most interesting tier for backups but it has many constraints, such as the need to pick every object inside the container and move them to the tier. So I will use cool.
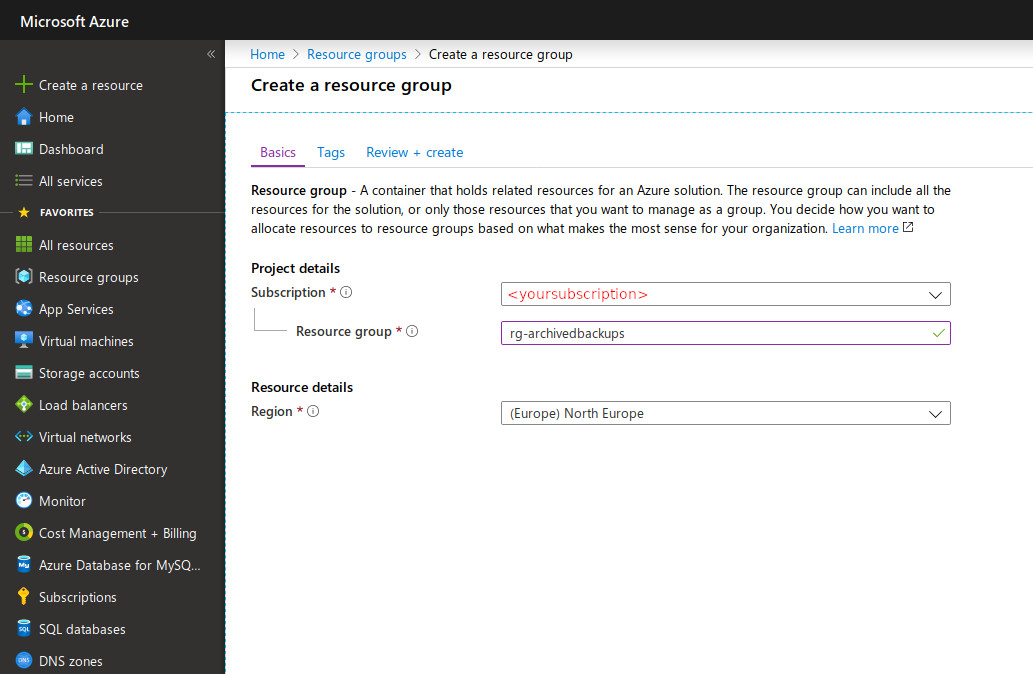
Create a Resource group and a Storage account
First you need to create a Resource group. Go to the Resource groups blade then click +Add. Take a look at Ready: Recommended naming and tagging conventions if you don't know how to name it. Select a region (does not really matters now).
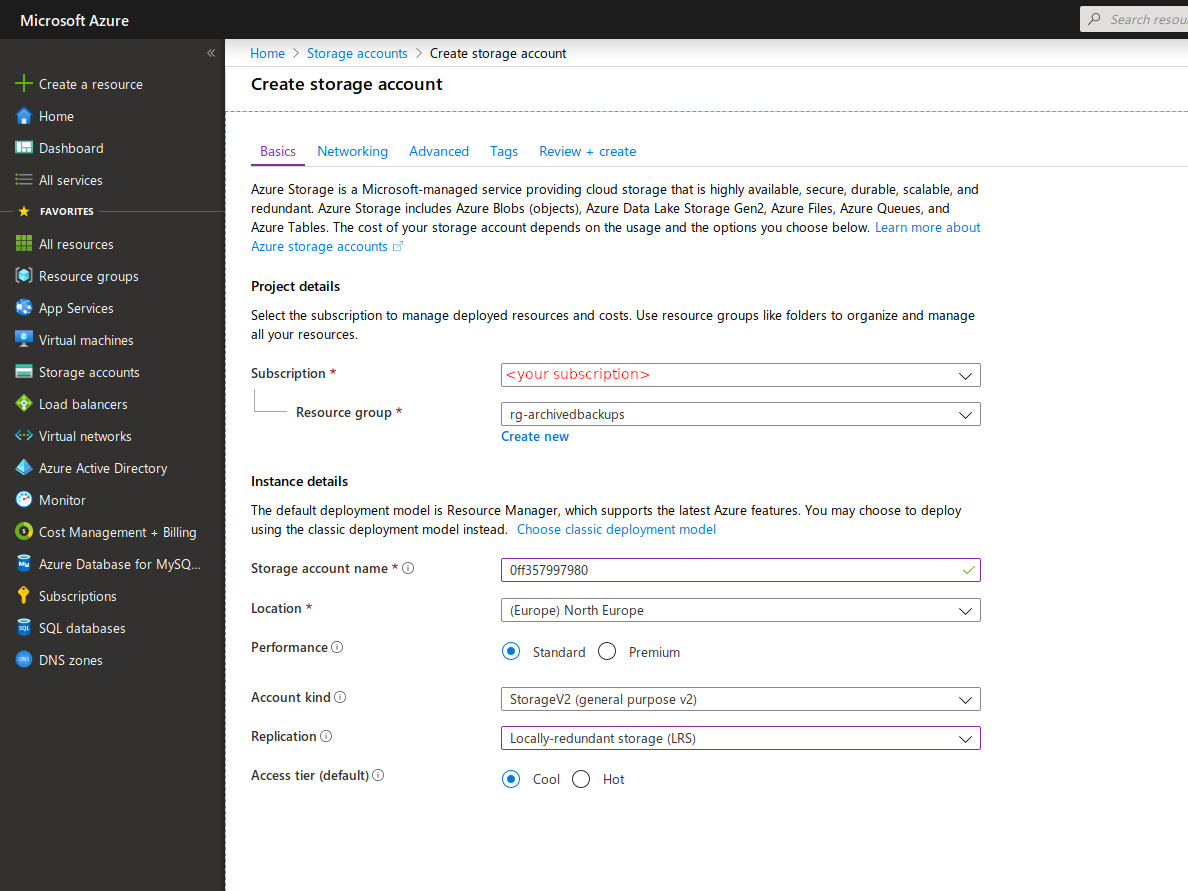
Now you need to create a Storage account. Go to the Storage accounts blade then click +Add.
Subscription: your subscription.
Resource group: the one you just created
Storage account name: must be unique accross Azure and as many limitations, so I recommend using a very short name + short random id.
Location: Select the location of your choice (choose a close one with an interesting pricing, see Azure Calculator)
Account kind:StorageV2
Replication:LRS
Access tier:cool
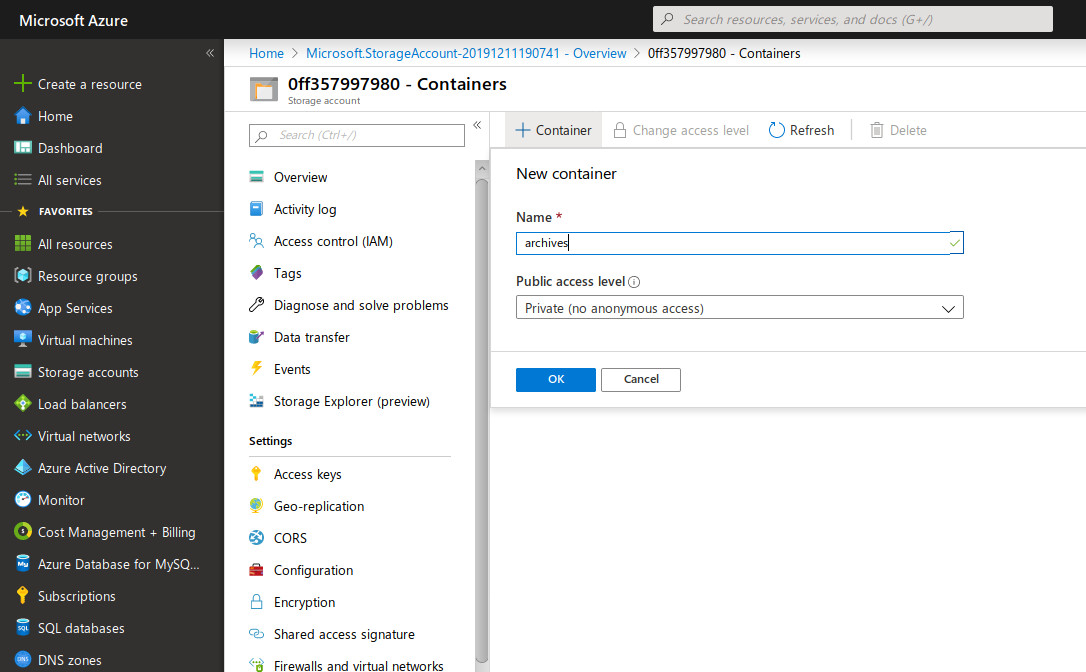
Now open you new Storage account and go to the Containers blade then click +Container. This time the name is private and does not need to be unique. Make sure the Public level access is set to Private (no anonymous access).
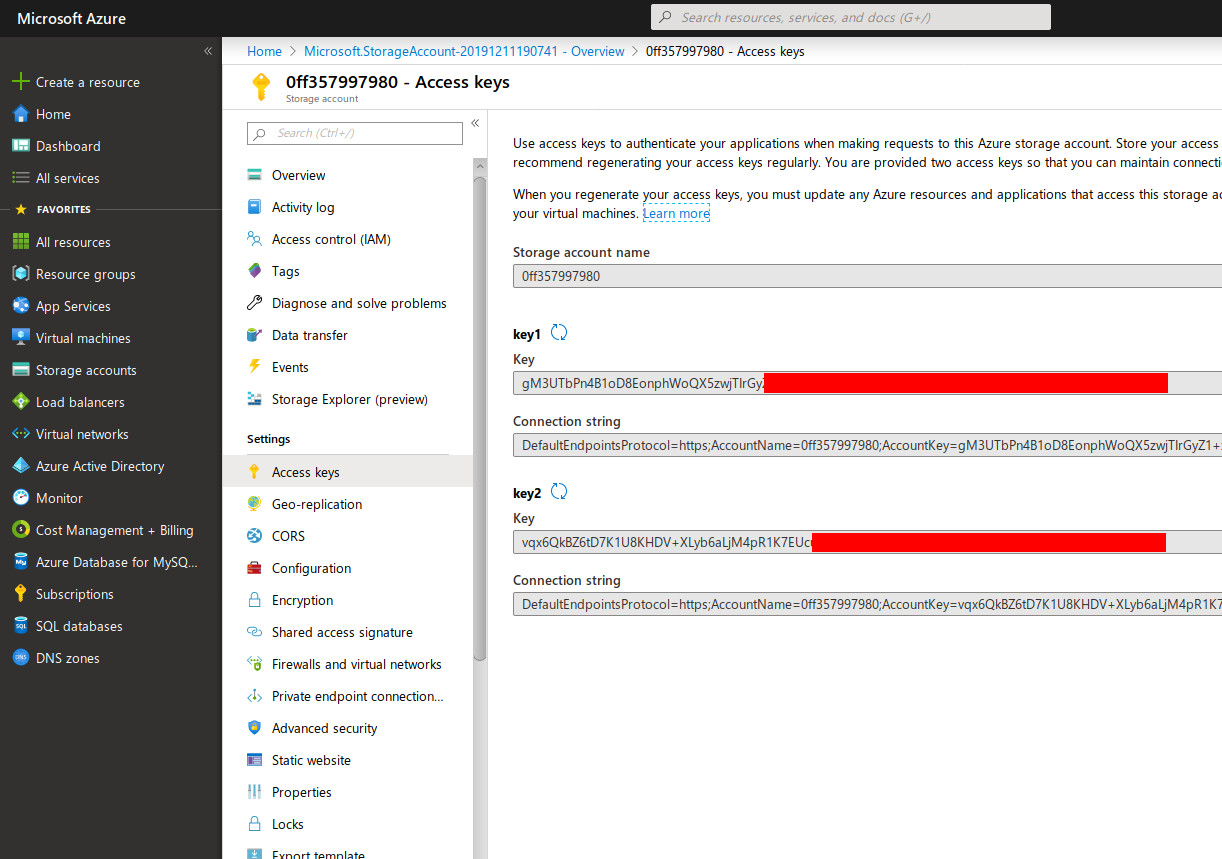
Go to the Access keys blade and retrieve the value of key1 or key2. These key are private and should not be shared with anyone because they basically give full access to the storage account and the data inside.
Configure Duplicati
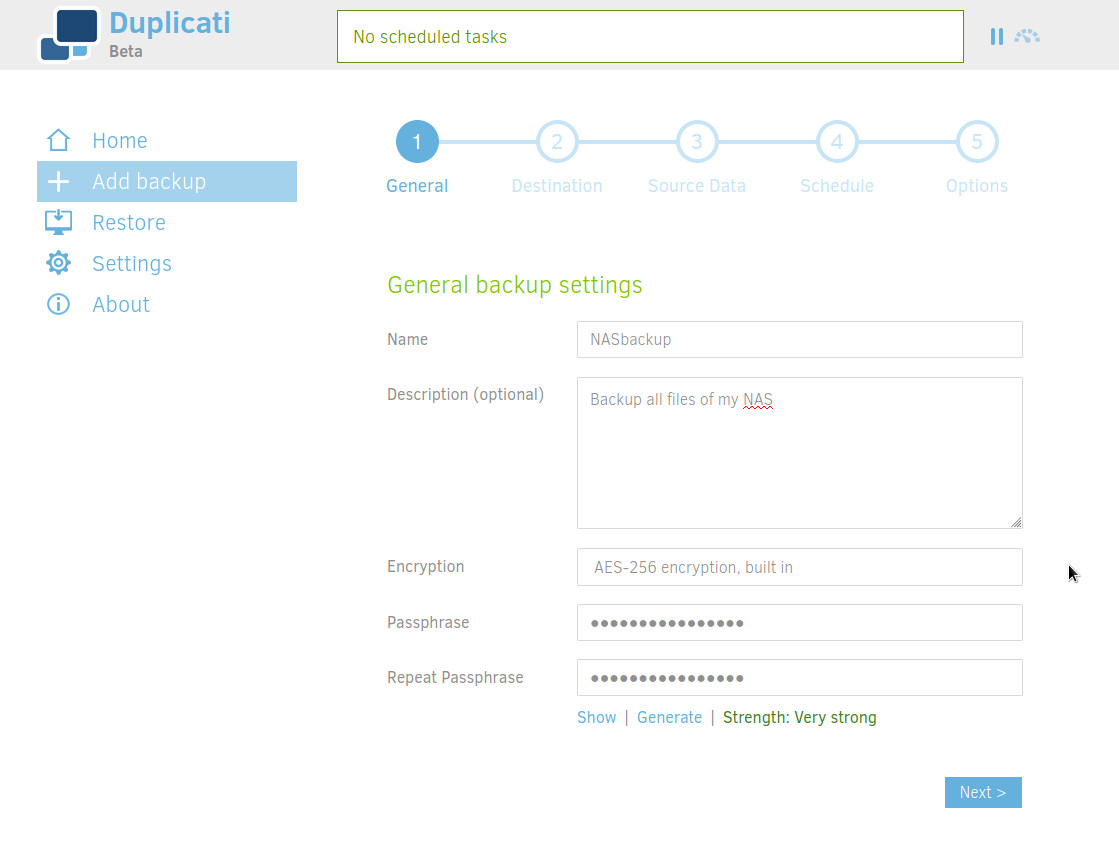
Go into the Web UI then + Add backup > Configure a new backup.
Enter a name, a description and a very strong encryption passphrase (if you forget this passphrase, you wan't be able to decrypt your backups).
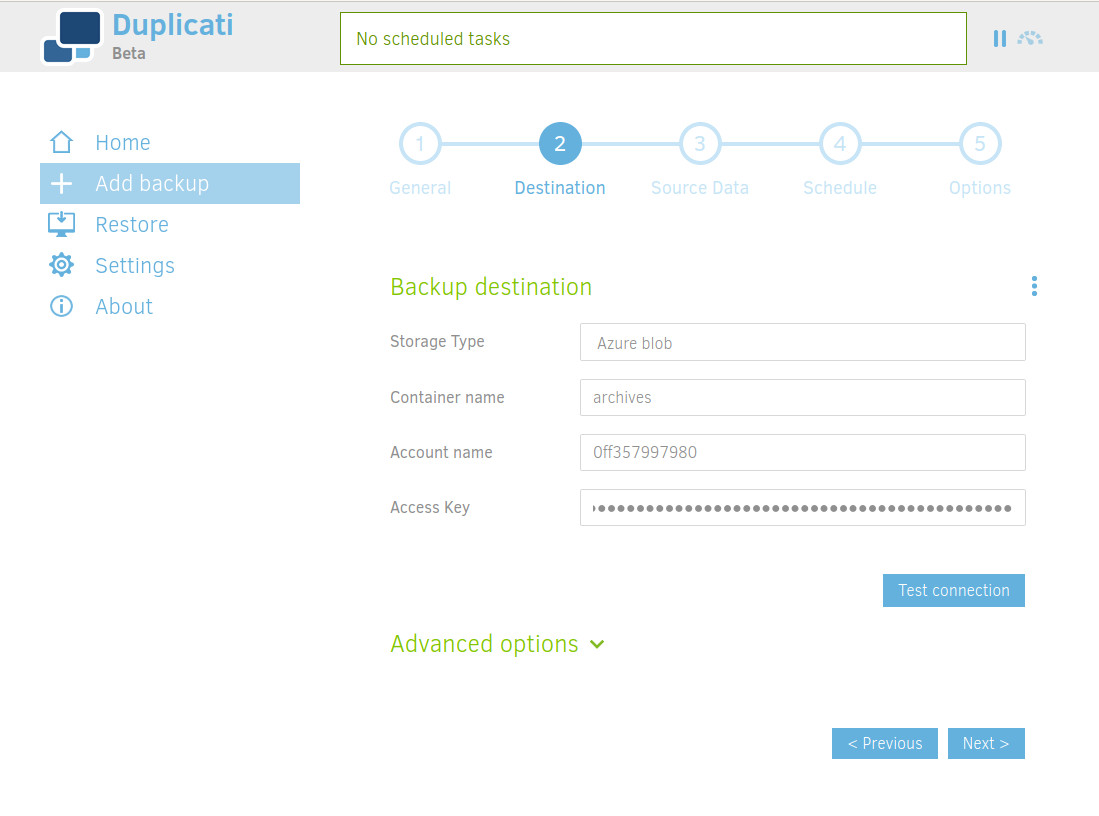
Select "Azure blob" for Storage type and set your credentials.
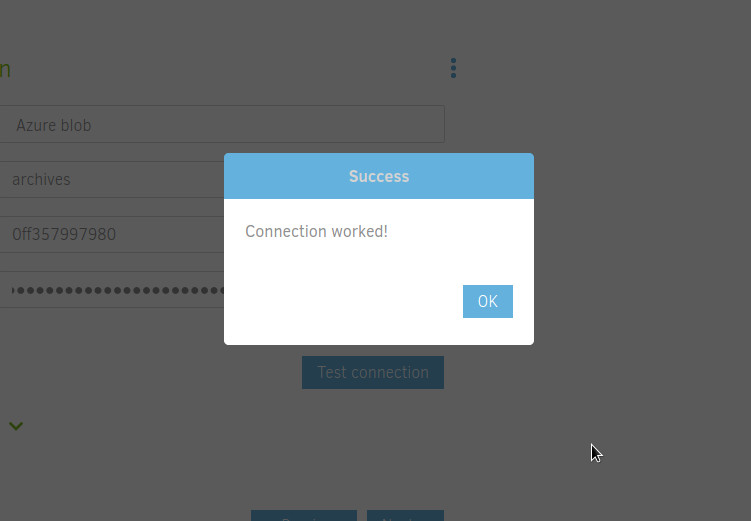
Click Test connection to make sure Duplicati can reach your Azure container.
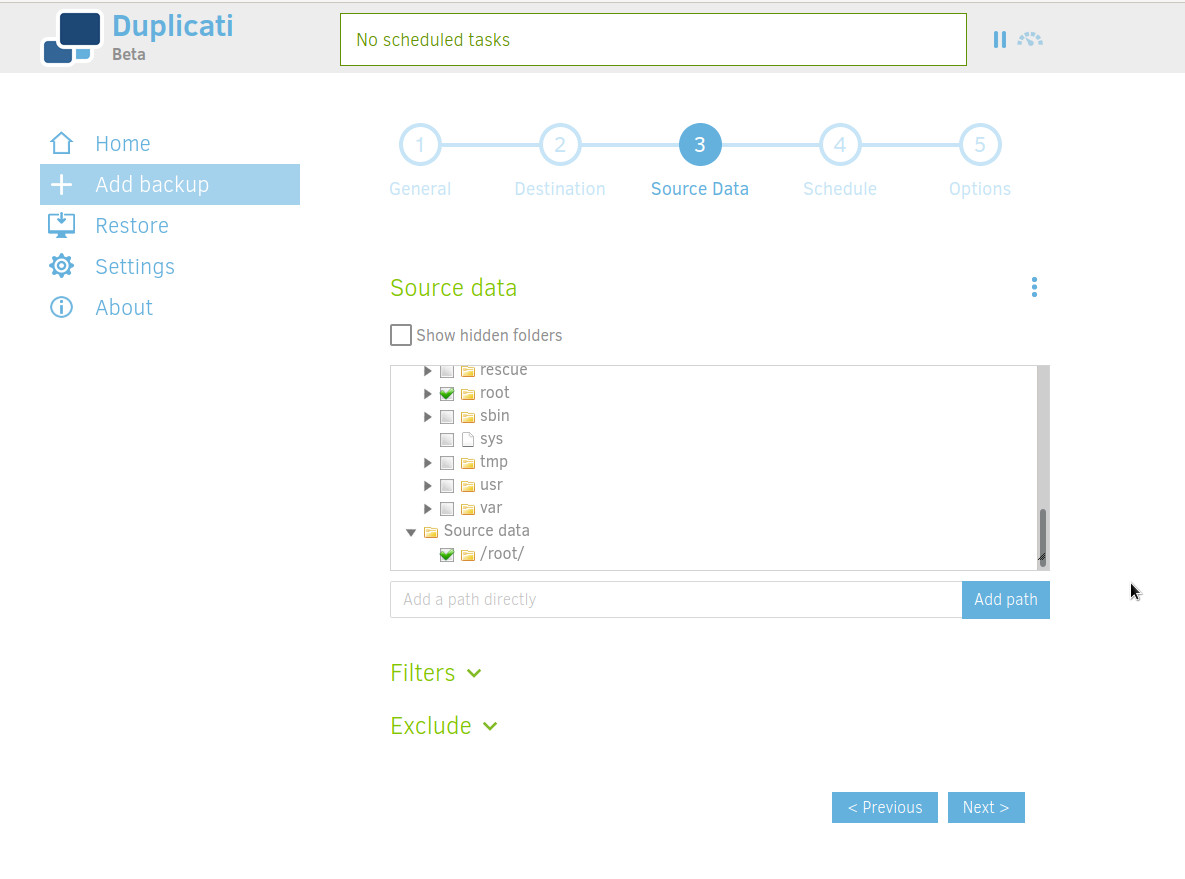
Select the files you want to backup.
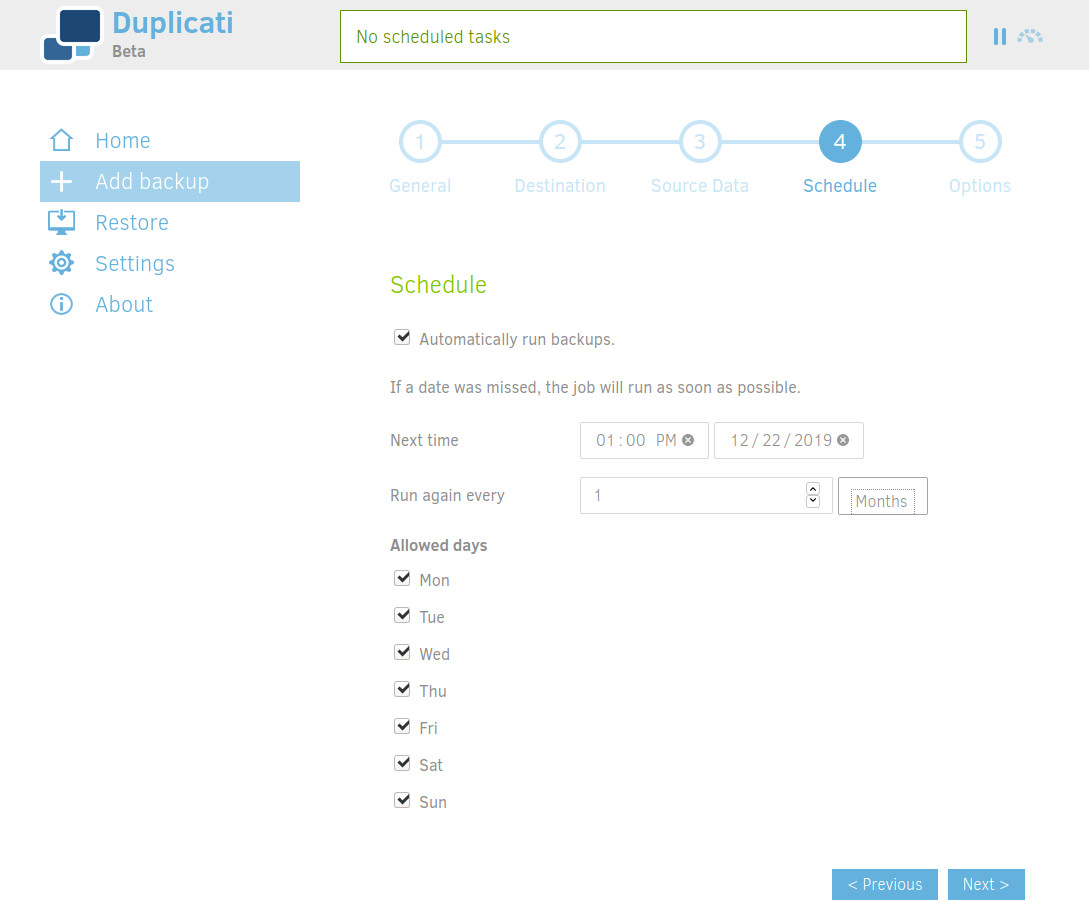
Schedule your backups. For me, monthly is enough.
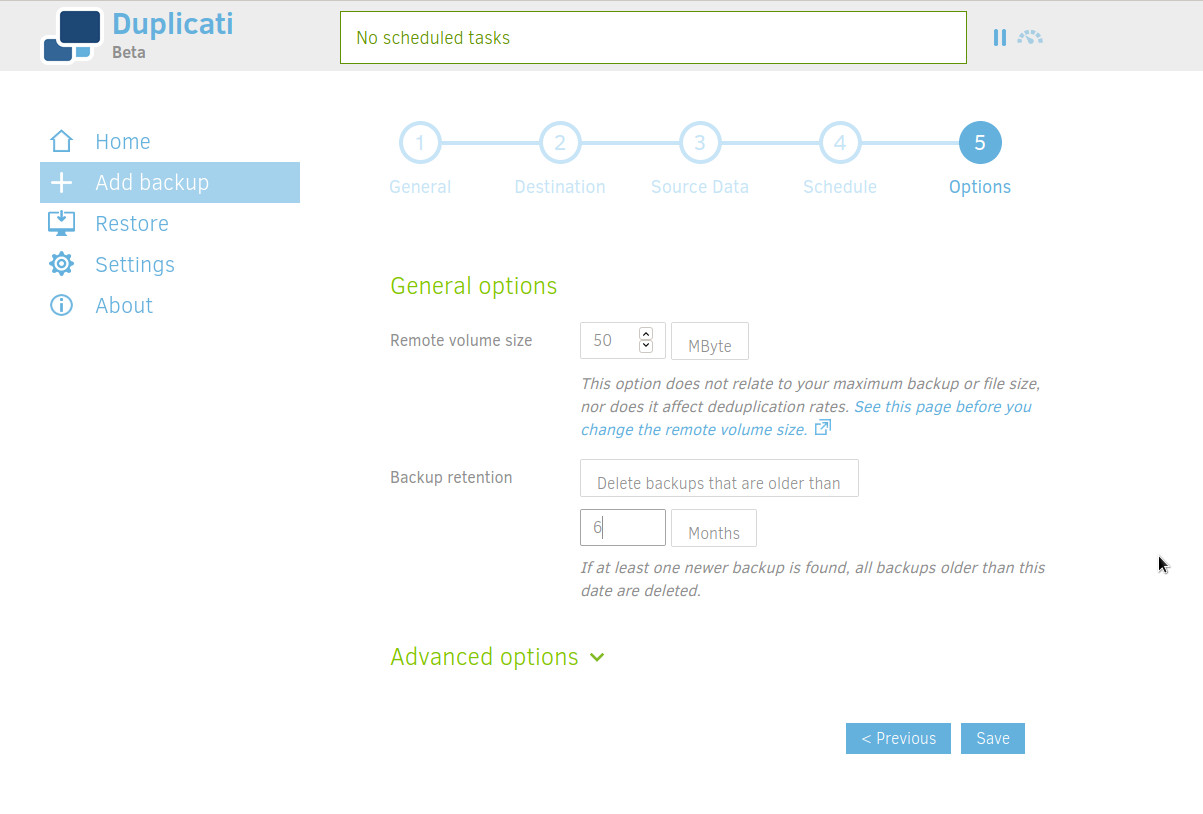
Duplicati will not copy your files one by one but use "volumes". To select the size of each block, read this documentation. Smaller means more transactions but better de duplication. Bigger means less transactions but less optimized de duplication. If you have the bandwith, go for higher chunks. 1 Gbyte seems to be a good value for me. More is not good, takes too much resources.
You can also set a retention, for me it's 6 months.
Et voila, just run your backup now!
Pricing considerations
It is not easy to estimate monthly charges. It depends not only on used storage, but also on write and read operations. Here is how much I pay:
J'utilise depuis quelques années un routeur ASUS RT-AC66U branché sur la freebox en bridge, principalement pour avoir du WiFi en 5GHz (le 2,4 étant saturé chez moi) mais aussi pour des fonctionnalités qui n'existaient pas quand je me suis abonné, par exemple le pare-feu et les dns ipv6. Ce montage fonctionne plutôt bien mais le routeur arrive aujourd'hui à ses limites :
Problèmes de performances avec OpenVPN (client et serveur) probablement à cause du CPU faiblard (MIPS 600 MHz). Les débits ne dépassent pas 1 Mbps.
Le firmware alternatif ASUS Merlin que j'utilisais a abandonné le support du RT-AC66U. J'ai du rebasculer sur le firmware ASUS officiel, toujours maintenu mais avec beaucoup moins de fonctionnalités.
J'envisage donc de changer de routeur et de mettre à niveau ma stack réseau avec au passage un ou plusieurs switches supportant les VLANs. J'ai envisagé plusieurs pistes :
Partir sur un routeur Mikrotik, car j'ai déjà travaillé avec ce matériel et j'adore RouterOS. De plus les prix sont très raisonnables.
Acheter un Linksys WRT (les gros routeurs bleus) car ces modèles ont l'air d'avoir une grosse communauté et énormément de firmwares alternatifs toujours maintenus.
Miser sur un APU Alix + pfSense / OPNsense. L'intérêt du x86 est que quasiment tous les OS fonctionnent dessus en natif.
Le routeur Linksys WRT a été rapidement éliminé car je prends le risque de retomber dans la même situation qu'avec le RT-AC66U, à savoir les firmwares communautaires qui ne sont plus maintenus ou trop limités.
J'ai été très tenté par un routeur Mikrotik malheureusement le support d'OpenVPN est extrêmement sommaire et ne correspond pas à mon besoin. Il est possible d'utiliser de l'IPsec (en IKEv2) mais pour une raison que j'ignore le flux ne passe pas à travers ma Freebox.
L'achat d'un APU Alix en x86 s'impose donc. Pour rappel, il s'agit d'un des nombreux modèles de SBC (Single Board Computer) au format mini-ITX construit par PC Engines. Grands fans de CPU AMD à basse consommation et de multiples interfaces réseau, ils sont très prisés pour faire des routeurs. En prime l'architecture x86-64 permet de faire tourner quasiment n'importe quel OS: Windows, Linux, FreeBSD, OpenBSD... ce qui donne au final un petit serveur mieux qu'un Raspberry Pi, même si le prix est bien plus élevé. L'inconvénient des APU Alix est qu'ils ne sont pas vendus dans la plupart des boutiques françaises, il faut donc aller chercher sur Amazon, eBay, Varia Store, ou d'autres revendeurs.
Pas de Wifi sur ce modèle, je vais devoir brancher mon Asus RT-AC66U configuré en mode point d'accès. En fait il est possible d'avoir du wifi directement sur le routeur Alix, mais c'est plus compliqué quand on veut du double bande 2,4 et 5 GHz car il faut deux cartes.
Reste à choisir l'OS qui sera installé pour faire office de routeur. Pour cela j'ai testé dans des machines virtuelles pfSense, OPNsense et Endian. Voici les résultats de ce POC :
Endian a une interface web trop limitée qui n'a quasiment pas évolué au cours des dernières années et ne permet pas de gérer un serveur OpenVPN, il faut passer par la CLI. J'ai donc abandonné assez rapidement cette solution.
OPNsense n'a pas été facile à prendre en main, l'interface moderne n'est pas très intuitive mais au final j'ai pu faire tout ce que je voulais. Malheureusement ma première mise à jour s'est faite dans la douleur, et lors de la seconde j'ai perdu la fonctionnalité de serveur DHCP. J'ai aussi de gros problèmes de lenteurs de l'interface avec Linux + Firefox ESR alors qu'avec Chrome pas de problèmes. Je n'ai donc pas un bon retour d'expérience concernant la fiabilité du produit.
pfSense est donc le gagnant par élimination. L'interface est différente d'OPNsense mais les fonctionnalités et la logique sont les mêmes. Le système de mises à jour est différent puisqu'il ne fonctionne pas par parquets mais au niveau de l'image dans son ensemble.
Il faut maintenant que je prenne le temps de configurer tout ça.
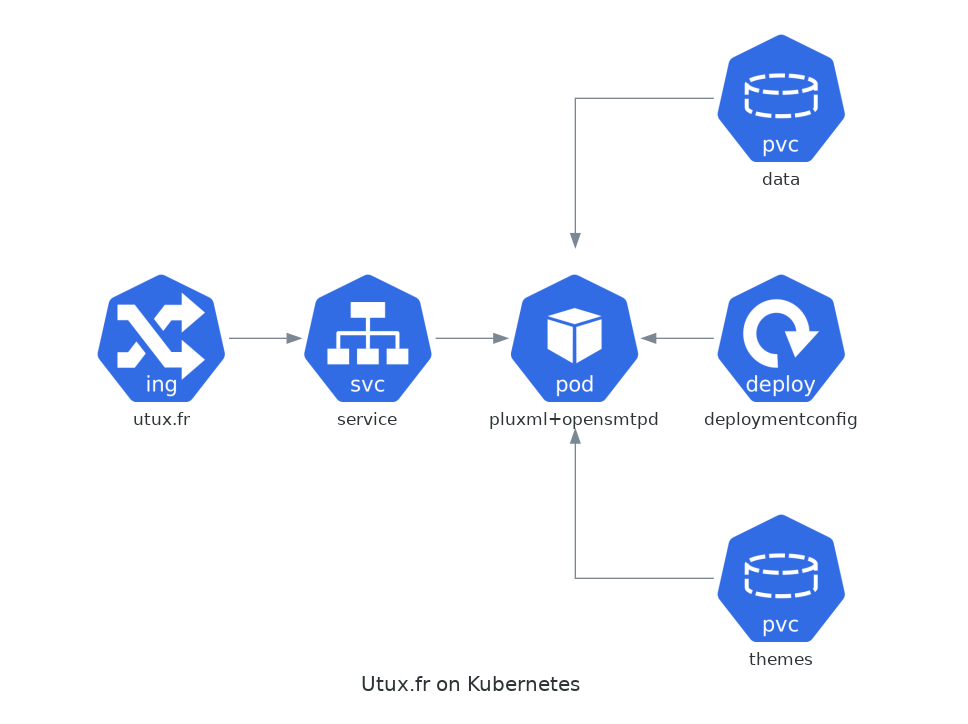
Kubernetes est probablement la technologie la plus complexe sur laquelle j'ai pu travailler cette année, à tel point que j'ai longtemps été réticent à m'y frotter. J'ai tout de même choisi de me faire violence et de persévérer car ce domaine est très valorisant et très valorisé. Utiliser un outil dans le cadre d'un réel besoin est le meilleur moyen pour apprendre, c'est pourquoi j'ai décidé de migrer mon blog et d'autres sites. Voici une vue d'ensemble du fonctionnement du blog dans Kubernetes, en sachant que le pod est composé d'un container OpenSMTPD (pour le formulaire de contact) et bien entendu d'un container Pluxml :
Note : Fait avec Diagrams (schema as code). L'Ingress Controller est Traefik (j'en parle plus bas).
Le changement n'a pas été instantané, loin de là, à vrai dire j'avais ce projet de côté depuis plus de 1 an. Mon idée de départ était de créer un cluster a plusieurs nœuds mais cela ajoute une contrainte au niveau du stockage, en effet il faut des volumes accessibles en réseau. La question des coût s'est posée également car mon blog n'est pas suffisamment important pour justifier 4 serveurs (3 noeuds + 1 NAS). J'ai donc fait des concessions et accepté d'utiliser un cluster Kubernetes à 1 nœud, avec la Storage Class par défaut de k3s (local-path). C'est donc un premier pas timide mais l'objectif est de me familiariser avec Kubernetes.
J'ai utilisé k3s, le Kubernetes Lightweight de Rancher. Cette distribution a l'avantage d'être facile à installer (une commande curl) et d'avoir une emprunte mémoire assez limitée (même si ça reste beaucoup plus élevé que Docker). Par contre elle n'est pas miraculeuse et le côté "lightweight" s'est fait en excluant ou limitant certaines features. Par exemple pour la gestion des Ingress on a droit à un Traefik built-in en version 1.7 (donc legacy) absolument pas documenté pour la gestion des certificats Let's Encrypt. J'ai donc désactivé cette version et installé le Traefik 2.x de containous grâce à Helm. Cette version de Traefik est implémentée en tant que CustomResourceDefinition (aka CRD) et est documentée sur le site officiel. J'avoue quand même avoir passé 3-4 jours à faire fonctionner ces satanés certificats Let's Encrypt mais j'y suis finalement parvenu et j'ai beaucoup appris.
Un autre point sur lequel k3s est limité est la liste de Storage Classes. Dans Kubernetes, une Storage Class, est en quelques sortes un driver qui peut provisionner à la volée des PersistentVolumes (PV). Dans mon cas je comptais utiliser AzureFiles pour provisionner des partages depuis un Storage account sur Azure mais il semble que k3s ne l'implémente pas. En lisant cette documentation je crois comprendre que k3s ne propose qu'une Storage Class locale, c'est à dire sur le nœud qui exécute le pod. Quand aux backends supportés, je ne trouve pas de liste même si j'ai pu valider que NFS fonctionne bien.
Migrer le blog dans Kubernetes m'a déjà permis d'apprendre beaucoup de choses. Rien de plus gratifiant que le sentiment "j'ai compris !!!" après avoir passé des heures à essayer en vain de faire fonctionner une ressource. J'espère me motiver un jour à ajouter d'autres nœuds dans mon cluster, quand j'aurai résolu le problème du stockage.
Attention, cet article va exploser le compteur de buzzwords.
J'utilise Docker en standalone depuis bientôt 3 ans, d'ailleurs mon blog tourne dessus à l'aide de deux images : PluXml et OpenSMTPD - pour le formulaire de contact - que j'ai moi-même réalisé. Sans dire que je maîtrise Docker, j'ai un niveau bien avancé. A côté de cela je travaille régulièrement avec OpenShift (la distribution Kubernetes commerciale de Red Hat) et même si je suis bien moins à l'aise qu'avec Docker, j'ai tout de même pas mal de connaissances.
Docker seul est un peu limité, on ne peut pas faire de clustering, ce qui est bien dommage car les containers et les micro-services s'y prêtent fortement. Il existe heureusement Swarm qui étend Docker au support d'une infrastructure à plusieurs nœuds.
D'un autre côté, le monde entier a les yeux rivés sur Kubernetes, le grand concurrent à Docker conçu dès le départ pour les clusters et la haute disponibilité. Ce dernier est très puissant mais aussi beaucoup plus complexe que Docker Swarm (surtout les RBAC dont je ne parlerai pas). Il faut aussi comprendre qu'on ne télécharge pas Kubernetes, on télécharge une distribution Kubernetes, et il en existe plusieurs. Dans le test de performances plus bas dans cet article je vais utiliser k3s, fourni par Rancher et grandement allégé et simplifié.
Alors, faut-il utiliser Swarm ou Kubernetes ?
Architecture
Docker Swarm
Le cluster se compose de nodes manager et workers. Les premiers sont chargés de piloter le cluster, les second exécutent les containers. Les commandes doivent être exécutées sur un des managers. Un système d'encapsulation UDP est en place entre les nodes, il permet aux réseaux des containers de se propager.
Dans Swarm on déclare des services, soit en cli soit en yaml (docker-compose). Le scheduler va ensuite provisionner les containers nécessaires au service sur un ou plusieurs workers, selon le nombre de replica demandé. Exemple :
$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
sb40x4z1zqkb httpd replicated 1/1 httpd:latest
owq6yurtagjg traefik replicated 1/1 traefik:2.1 *:80->80/tcp, *:443->443/tcp
On peut augmenter ou diminuer manuellement le nombre de replicas, il y a un load balancer interne qui va répartir le trafic de manière transparente. Un système d'affinités permet de lier les containers à une node en particulier, très pratique. Les services peuvent être mis à jour en rolling update, c'est à dire qu'on ne restart pas tous les containers d'un coup mais les uns après les autres, ce qui permet de ne pas interrompre le service. Un rollback est possible.
Et... c'est à peu près tout. Simple et efficace, mais aussi un peu limité il faut l'avouer. Swarm est un bon choix pour un usage personnel de part sa simplcité. Par contre on va voir que pour les cas d'usage avancés, Kubernetes est plus adapté.
Kubernetes
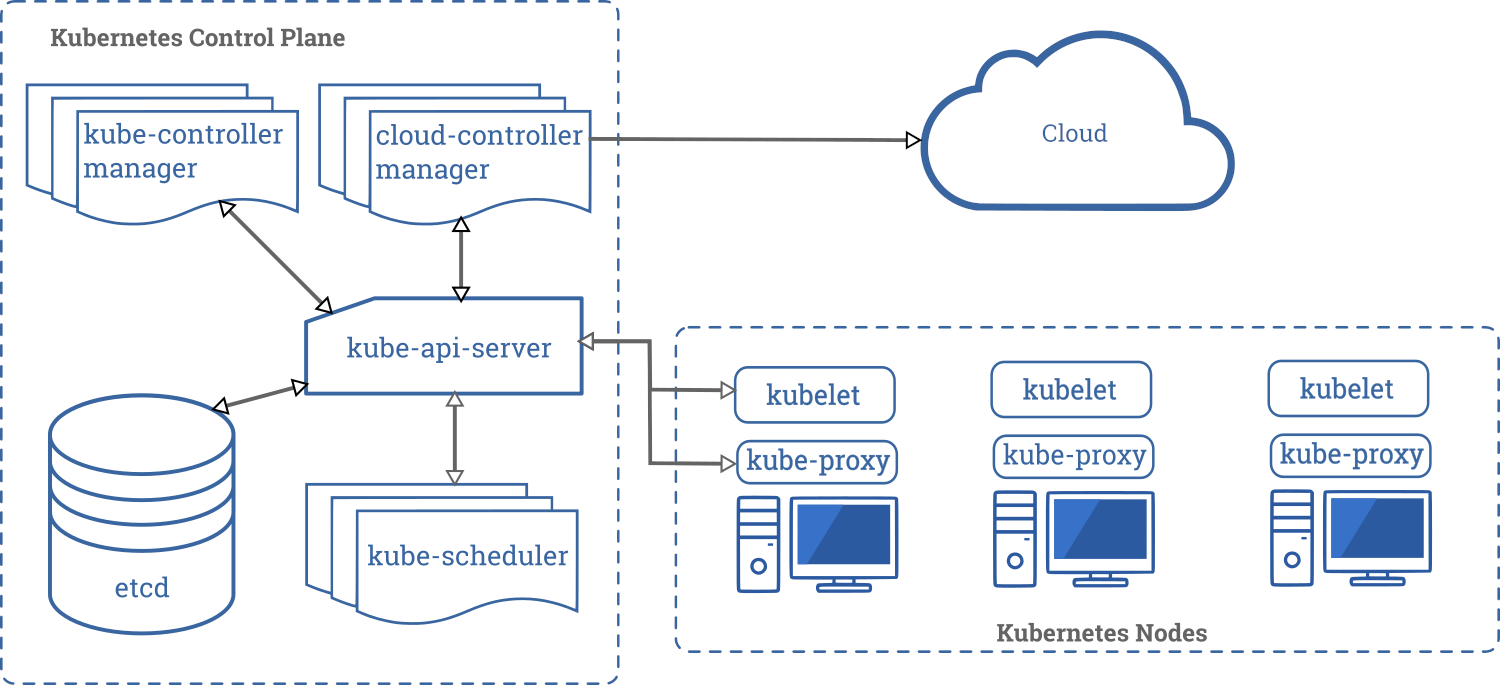
Accrochez-vous. Commençons avec l'architecture Infra.
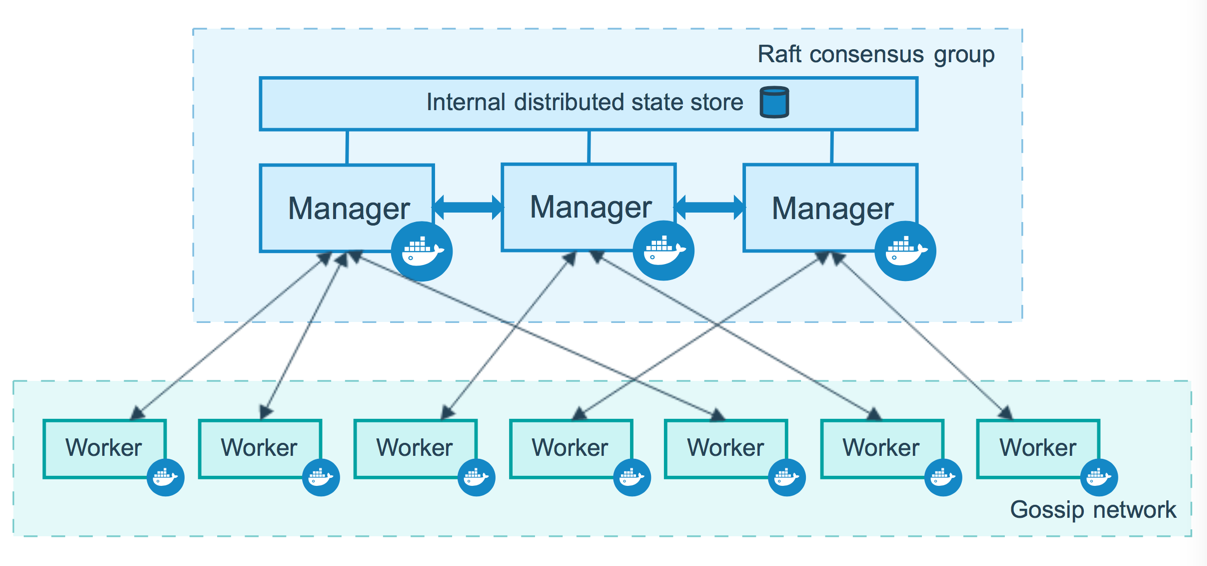
Le cluster est composé de nodes Control Plane (les masters ou managers) ainsi que des workers. Les Control Planes pilotent le cluster et l'API Kubernetes, à l'aide d'un système de configuration centralisé, qui est souvent basé sur etcd (selon les distributions) mais pas toujours. Par exemple, k3s utilise sqlite. Les workers ont un agent (kubelet) qui reçoit les instructions du scheduler. Là encore une encapsulation UDP est prévue entre les nodes pour permettre la propagation des réseaux des containers.
Attaquons maintenant le fonctionnement des ressources. Dans le cluster Kubernetes, tout est objet, tout est yaml ou json. C'est avec ça que l'on contrôle comment nos containers sont déployés et fonctionnent. Les types (kind) d'objets les plus courants sont :
Pod : Un espace logique qui exécute un ou plusieurs containers.
Service : Sert à exposer un ou plusieurs ports pour un pod, attaché à une IP privée ou publique.
DeploymentConfig : Défini ce qu'on déploie. Typiquement l'image à utiliser, le nombre de replica, les services à exposer, les volumes...
ReplicaSet : un contrôleur qui va vérifier que le nombre de pods en place correspond au nombre de replicas attendu. Scaling automatique possible.
PV, PVC : système d'attribution (automatique ou pas) de volumes persistants.
ConfigMap : objet permettant de stocker de la configuration, qui peut être ensuite lue et utilisée par les containers.
Namespace : Séparation logique des ressources, seules les ressources affectées au namespace en cours sont visibles.
Exemple d'utilisation :
$ kubectl -n web get all
NAME READY STATUS RESTARTS AGE
pod/svclb-httpd-rw7k5 1/1 Running 0 5s
pod/httpd-8647457dd7-s2j4d 1/1 Running 0 5s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/httpd LoadBalancer 10.43.80.117 10.19.2.73 80:30148/TCP 5s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/svclb-httpd 1 1 1 1 1 5s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/httpd 1/1 1 1 5s
NAME DESIRED CURRENT READY AGE
replicaset.apps/httpd-8647457dd7 1 1 1 5s
Par souci de simplification je ne parle pas du système de RBAC qui permet une granularité dans la gestion des droits, au prix d'une complexité (très) importante.
Kubernetes n'est pas aussi simple que Swarm mais il permet de faire beaucoup plus de choses. En fait on peut presque dire qu'on peut tout faire avec. Les namespaces sont une fonctionalité très pratique, tout comme le scaling auto et la possibilité d'éditer les objets avec la commande edit. En environnement pro, où vous allez gérer plusieurs clients, beaucoup d'applications et de fortes charges, Kubernetes est quasiment indispensable.
Fonctionnalités
Swarm
Kubernetes
Configuration yaml ou json
Oui
Oui
Commandes Docker
Oui
Non
CLI distant
Oui
Oui
Network inter-containers & DNS
Oui
Oui
Replicas
Oui
Oui
Scaling manuel
Oui
Oui
Auto-scaling
Non
Oui
Health probes
Non
Oui
Modification d'objets en ligne
Non
Oui
RBAC
Oui (EE)
Oui
Namespaces
Non
Oui
Volumes self-service
Non
Oui
Kubernetes est indéniablement plus complet, mais à quel point ces fonctionnalités sont-elles indispensables, surtout pour un usage en perso ? Et bien il y a à mon sens deux points que je trouve excellents dans Kubernetes et qui me manquent dans Swarm:
La modification d'objets en ligne. J'entends par là que la commande kubectl edit type/object permet de faire une modification à la volée, par exemple changer un port ou une version d'image dans un DeploymentConfig. Cela n'est à ma connaissance pas possible dans Docker, sauf avec docker-compose (stack dans le cas de Swarm) à condition d'avoir encore les fichiers yaml et que ceux-ci soient à jour.
Les namespaces. Pour éviter de mélanger plusieurs ressources de projets qui n'ont rien à voir, Kubernetes propose un système de namespaces. Par exemple je peux créer un namespace utux dans lequel je vais déployer mes images PluXml et OpenSMTPD, ce qui permet de s'y retrouver mais aussi de tout supprimer plus facilement si besoin. Les namespaces sont aussi très utiles lorsque vous partagez ou louez votre Cluster Kubernetes, chaque utilisateur a ainsi son espace dans lequel il ne voit que ses ressources.
Cependant Docker et Docker Swarm sont beaucoup plus simples et n'utilisent que des composant upstream.
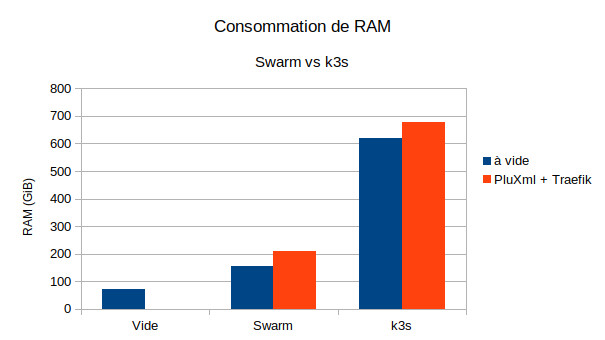
Consommation de ressources
Tests effectués sur des instances DEV-1S de chez Scaleway (2 vcpu, 2GiB RAM, no swap). Le système d'Exploitation est Debian 10 Buster x86_64.
Système seul: RAM 70.9M/1.94G
Swarm seul: RAM 155M/1.94G
Swarm + Traefik + PluXml (apache): 209M/1.94G
k3s seul: RAM 619M/1.94G
k3s + Traefik + PluXml (apache): 678M/1.94G
Si vous comptez monter un cluster de Raspberry Pi avec 1GB de mémoire, vous pouvez oublier k3s/Kubernetes qui en consomme déjà presque 75% à vide. Si vous avez les moyens de payer des serveurs de calcul un peu plus costauds, avec 16 ou 32GB de mémoire, la différence sera alors négligeable.
Les pré requis pour certaines distributions comme OpenShift sont beaucoup plus importants: 4 vcpus et 16GiB de ram pour chaque master (x3), 2 vpus et 8GiB de ram pour les workers (à multiplier par 4 si vous montez l'infra de logging ElasticSearch). C'est la raison pour laquelle je ne l'ai pas utilisé dans ce comparatif, il est hors compétition.
Exemple
Docker Swarm
Exemple simple avec la création d'un container apache vide :
$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
8pxc580r3yh6 test_web replicated 1/1 httpd:latest *:8080->80/tcp
$ curl http://127.0.0.1:8080
<html><body><h1>It works!</h1></body></html>
Kubernetes
Reprenons notre container apache vide :
apiVersion: v1
kind: Service
metadata:
name: web
labels:
app: web
spec:
ports:
- port: 80
selector:
app: web
tier: frontend
type: LoadBalancer
---
apiVersion: apps/v1 #
kind: Deployment
metadata:
name: web
labels:
app: web
spec:
selector:
matchLabels:
app: web
tier: frontend
strategy:
type: Recreate
template:
metadata:
labels:
app: web
tier: frontend
spec:
containers:
- image: httpd:latest
name: web
ports:
- containerPort: 80
name: web
Chargons ces objets :
$ kubectl create namespace test
$ kubectl -n test create -f web.yaml
Vérifions :
# kubectl -n test get all
NAME READY STATUS RESTARTS AGE
pod/svclb-web-jqs6j 0/1 Pending 0 7m17s
pod/web-774f857549-dstkz 1/1 Running 0 7m17s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/web LoadBalancer 10.43.109.52 80:30452/TCP 7m17s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/svclb-web 1 1 0 1 0 7m17s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/web 1/1 1 1 7m17s
NAME DESIRED CURRENT READY AGE
replicaset.apps/web-774f857549 1 1 1 7m17s
$ curl http://10.43.109.52
<html><body><h1>It works!</h1></body></html>
Conclusion
Kubernetes est plus complet que Swarm mais aussi plus compliqué. Il n'est pas toujours facile de choisir entre les deux, mais je vous donne les conseils suivants :
Pour un usage personnel, Docker standalone ou Docker Swarm sera votre choix par défaut, même si rien ne vous empêche d'essayer Kubernetes :)
Si vous êtes pragmatique ou que vous souhaitez travailler sur les containers, alors ce sera Kubernetes. C'est l'outil en vogue plébiscité par tout le monde et c'est ce que vous devez avoir sur votre CV.
Pour un usage en entreprise, Kubernetes sera incontournable car il y a de nombreuses offres dans le Cloud et On-Premise. Aks ou OpenShift sur Azure, Eks chez Aws, pour ne citer que les plus connus. Tout l'écosystème des containers est focalisé sur Kubernetes et les namespaces vous serons indispensables dans un contexte multi-client.
Pour finir, un court retour d'expérience sur l'utilisation de Kubernetes en entreprise. Tout d'abord, soyez conscient que votre cluster, vos clients et vos utilisateurs vous poseront de nombreux défis. Ne pensez pas que Kubernetes va résoudre magiquement tous vos problèmes et que vos admins vont se tourner les pouces, bien au contraire. Dans le cas d'une plateforme On-Premise, prévoyez 2 admins à temps plein au minimum. Ensuite, vous devez disposer de compétences dans quasiment tous les domaines : réseau, stockage, système, middlewares et surtout avoir une bonne maitrîse de la Elastic Stack (ELK ou EFK) puisque vous aurez à gérer les logs de vos nodes et containers.
Avec cet article j'espère avoir bien présenté les différences entre Docker Swarm et Kubernetes et fourni quelques pistes à ceux qui hésitent :)